


If you are an engineering leader exploring LLMs, you have likely encountered a confusing naming convention on HuggingFace. You see Llama-3-8b (the Base model) and Llama-3-8b-Instruct.
What is the difference? Is it important? When to use each?
⚠️ Career Update: I am currently exploring my next Senior Staff / Principal role. While I search for the right long-term match, I have opened 3 slots in February for interim advisory projects (specifically Resilience Audits and SLO Workshops). If you need a “No-BS” diagnosis for your platform, check the project details and apply here.
This article answers those questions with examples that are familiar to senior developers and engineering leaders.
Note: this content is partially generated by AI (Gemini) and edited by me after understanding and verification.
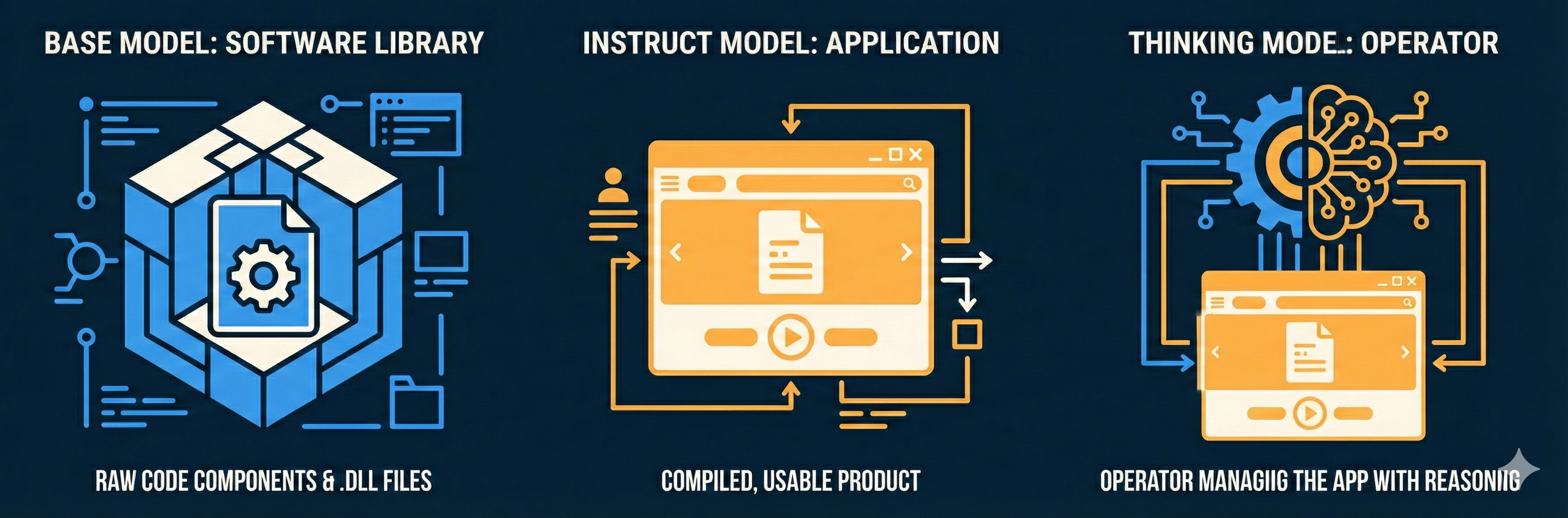
A metaphor: lib vs app vs operator
For engineers accustomed to deterministic systems, the difference between these two model types is like the difference between a raw, unlinked library and a compiled, executable binary.
Here is the technical breakdown of what is actually happening under the hood, minus the AI hype.
1. The Base Model: lib
A Base Model (or Foundation Model) is the result of the pre-training phase. It has consumed terabytes of text and learned a statistical probability distribution. Its only function is: Given a sequence of tokens, predict the next most likely token.
It has no concept of “questions,” “answers,” or “instructions.” It only understands patterns. As a probabilistic engine, it is designed to minimize entropy. It doesn’t know facts other than predicting the most likely next token based on training distribution.
Note: Since the internet is full of “FAQ” pages and StackOverflow threads, Base models do statistically understand the concept of a Q&A format. Base models can sometimes zero-shot answer questions just by luck of the distribution.

Suppose you prompt the model
What is the capital of France?
The model analyzes the pattern. In its training data (internet forums, datasets, books), a list of questions often follows a question. It tries to minimize entropy by generating more questions.
It may then respond
And what is the population of Paris? What is the French currency?
We can think of a base model as libc or a massive generic utility library:
It contains all the raw knowledge (functions, symbols, logic).
It has no entry point (
main()function).It has no opinion on how it should be used.
Use cases for Base Models
Code Completion: If you feed it
function calculateTax(amount) {, it naturally predicts the next lines of code because that pattern exists in its training data.Few-Shot Learning: You can “program” it by providing examples in the prompt, effectively forcing a pattern it can complete.
Fine-Tuning: This is the most critical use. You don’t deploy
libc; you build on top of it. You take a Base Model to fine-tune it on your proprietary data format (e.g., specialized medical records or legacy COBOL translation).
2. The Instruct Model: app
An Instruction Fine-Tuned (IFT) model is basically a Foundation Model (Base Model) that has gone through Post-Training.
Behind the scene the chat/instruct models are just text-completion models relying on specific markers to annotate which part of the conversation is said by whom.
For example, when you send this JSON array for completion (source):
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"},
{"role": "assistant", "content": "Hi! How can I help you today?"},
{"role": "user", "content": "What's the weather?"},
]It is converted to the following using a template (typically Jinja):
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
Hello!<|im_end|>
<|im_start|>assistant
Hi! How can I help you today?<|im_end|>
<|im_start|>user
What's the weather?<|im_start|>assistantThe instruct models are sometimes called chat models. The difference is subtle but important:
Chat models: are trained to have a conversation and are usually simpler. These models often have
-chatin their model name (e.g. MBZUAI-IFM/Llama-3.1-Nanda-87B-Chat).Instruct models: are chat models but also trained to execute tasks. These models often have
-itin their model name (e.g. google/gemma-3-27b-it)
While the capability difference exists, model vendors are increasingly just labeling everything as -Instruct to indicate "this is the one you can talk to”.
Regardless of the type, creating a chat or instruct model typically involves two steps:
SFT: Supervised Fine-Tuning (OpenAI docs)
RLHF: Reinforcement Learning from Human Feedback
Step 1. SFT
SFT aligns the probability distribution with a specific output format. It restricts the model’s search space to helpful responses rather than the generic text completion.
Think of it as “unit testing” but for training AI models.
The base model is fed a massive dataset of (Instruction, Response) pairs.
It is then punished (mathematically, via loss functions) whenever it deviates from the expected response.
Loss function is a mathematical formula used to quantify the difference between a model's predicted output and the desired "ground truth" response from a training dataset.
This teaches the model a new behavior: When you see a prompt, do not autocomplete it. Execute it.
Step 2: RLHF
Think of it as “user acceptance testing” (UAT) but for training AI models.
Reinforcement Learning from Human Feedback (RLHF) aligns the model with human preference.
The model generates three possible answers.
A human (or a strong teacher model) ranks them: A > B > C.
The model updates its weights to maximize the reward (producing “A” type answers).
Note: this is when human biases and sycophancy creep in: “You are absolutely right”! 😄
When you use ChatGPT, Claude, or Gemini, you are interacting with an Instruct Model that follows your (and the AI vendor’s) orders.
3. The Thinking Model: app with an operator
If the Base model is a library and the Instruct model is an App, the Thinking Model is like having an operator who knows how to use the “app”.
It is particularly useful for vague or complex tasks where the instructions alone cannot reliably lead to a solution.
The idea is simple: use LLM as a built-in chain of thought reasoning engine to circumvent its inability to think in abstract terms.
Chain-of-Thought (CoT) is a prompting technique that instructs large language models (LLMs) to break down complex problems into intermediate, step-by-step reasoning processes.
It is especially useful for tasks that require calculation, common sense, or multi-step logic.
The simplest implementation is to ask an Instruct model to think in steps:
Let’s think step by step.
That’s called Zero-Shot CoT.
“Thinking” models push that idea further by specifically training the model using:
Large-Scale Reinforcement Learning (RL): algorithms that reward the correct final answer rather than a specific path. This teaches the model to independently discover productive “chains of thought” that lead to accurate results.
Chain-of-Thought (CoT) Specialization: to generate “reasoning tokens” or internal thinking blocks. These tokens allow the model to break down complex tasks, self-correct, and try alternative strategies before producing a final response.
Process Reward Models (PRMs): grade the quality of individual intermediate reasoning steps during training to help the model internalize methodical thinking patterns.
OpenAI’s o1 or DeepSeek-R1 are examples of thinking models.
The Code: How it looks
While the input is a standard prompt, the model’s output contains a distinct “thought” block before the final answer.
// The Request (Standard)
{
"model": "deepseek-reasoner",
"messages": [{ "role": "user", "content": "Optimize this O(n^2) sort function." }]
}
// The Response (Thinking Process)
{
"content": "<think>
1. User wants optimization. Current is Bubble Sort?
2. Input size is not specified. If small, insertion sort is fine.
3. Assume large input. Merge Sort vs Quick Sort?
4. Wait, is memory constrained? Checking requirements...
</think>
Use Quicksort for average O(n log n) performance..."
}
Open-weight models (like DeepSeek-R1) expose this trace, while closed models (like o1) hide it (in the name of “safety” or competitive advantage) and hide or summarize it.
Regardless, the UI usually hides the thought process by default. The most obvious clue for the user is that it takes longer time to get a response because the model is “thinking”. I put thinking in quotes because the current version of AI is inherently incapable of thinking in abstract terms but rather mimics thinking out loud in the same context window that is used to generate a response.
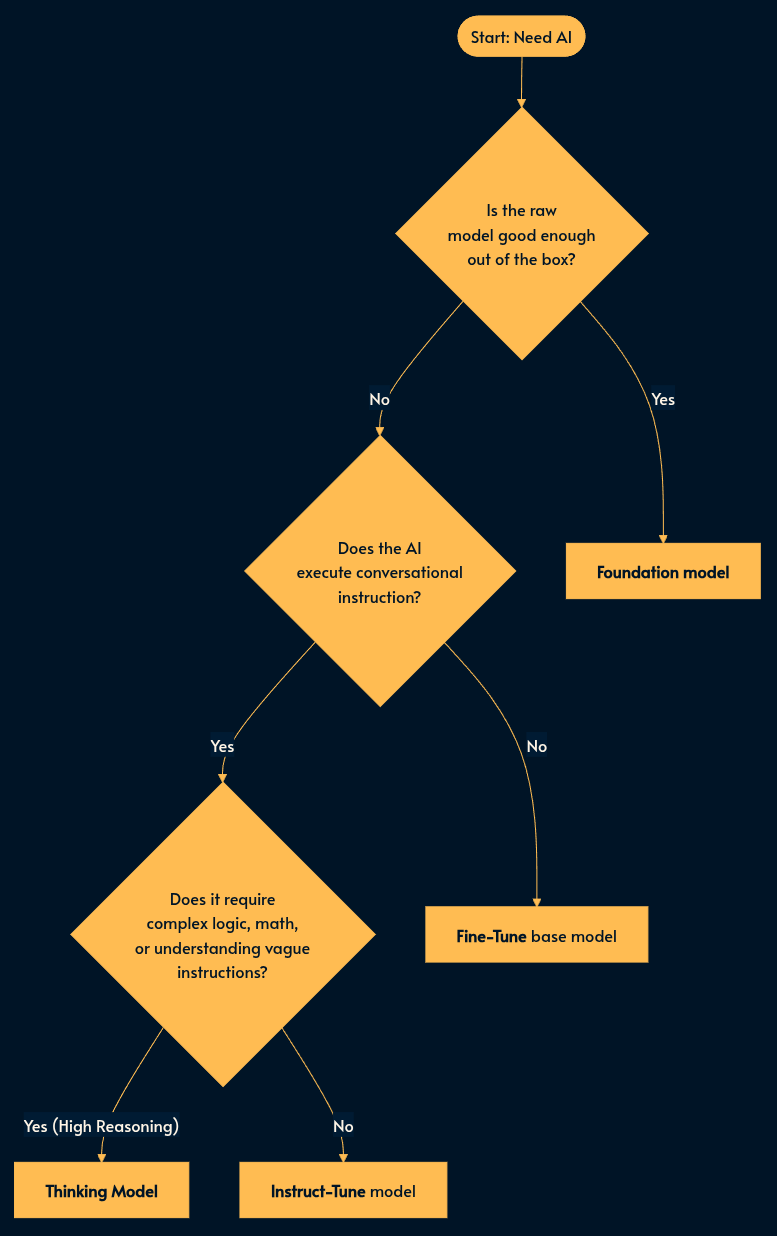
When to use which?
If you are building an AI feature, you now have three architectural choices:
The “App” (90% of use cases): Use an Instruct Model with Tool Calling (e.g. MCP, function calls, Skills). You want a conversational assistant that can look up data or do stuff. It’s fast, cheap, and lagom (Swedish for balanced/optimal) for most text tasks.
The “Operator” (5% of use cases): Use a Thinking Model. If the task involves vague requests, math, strict constraint satisfaction, or complex coding, you pay the latency penalty for the reasoning capability.
The “Domain Expert” (5% of use cases): Fine-tune a Base Model. Use this only if you need the model to speak a completely novel language (e.g., a proprietary legacy query language) where the “helpful assistant” training of Instruct models actively interferes with the syntax.
Recap
Base Model: Raw pattern matcher. Good for autocompletion and fine-tuning. Acts like a library.
Instruct Model: Fine-tuned for Q&A (
Application). Good for general chat and simple tasks. Acts like an app.Thinking Model: Reasoning engine (
Async Worker). Good for complex logic and planning. Acts like an operator.
As you build out your AI capabilities, default to Instruct models for applications, and reserve Base models for when you need to compile your own proprietary “binaries” from scratch.