


Failover and fallback are sometimes confused with each other. It is easy to see why:
They are both F-words! 😄 The words “fail” and “fall” are conceptually related.
They both rely on some predefined backup plan
They are both strategies to reduce the risk of failures
They both increase the system complexity and cost
You may use one or both in a given system architecture
We need to distinguish between relevant terms because what you think may not be what you say and what you say may not be what is heard and what is heard may not be what is implemented!
This article digs into different types of failover mechanisms, how they work, and some examples. In a follow-up article we will discuss fallback.
What is Failover?
Failover is a risk mitigation strategy to improve service continuity and reduce downtime.
How does failover work?
In a nutshell here’s how failover works:
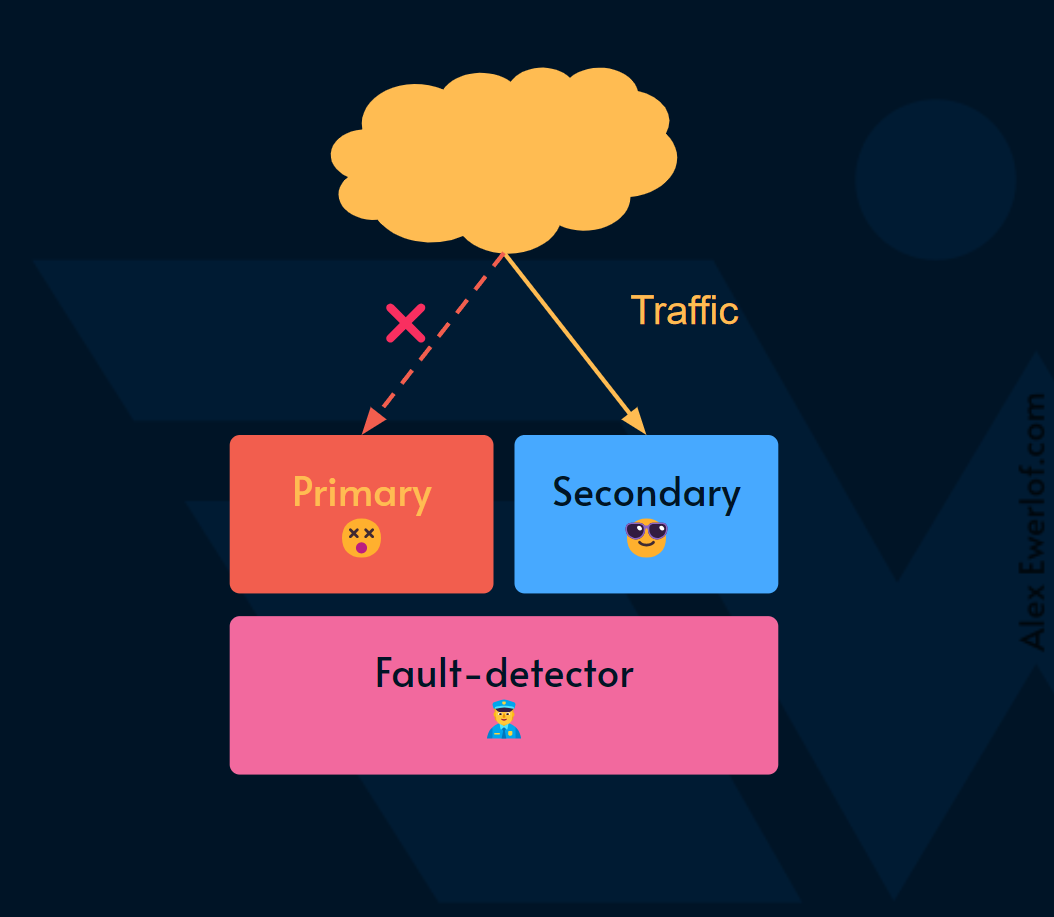
The primary system is responsible for handling the load while one or more secondary systems are on stand-by. The secondary systems are of the same type as the primary and sometimes are called replicas.

A fault-detection system continuously observes the behavior of the primary system
If a failure is detected in the primary system, the load is automatically shifted to the secondary systems

This buys time for the engineers or automation to fix the issue with the primary system
Once the issue is resolved, the primary system takes over

Key characteristics of Failover
Service Continuity: The goal of failover is to minimize or eliminate the impact of failures from the consumer by switching to the secondary system. As far as the users are concerned the system is just working as usual without perceivable degradation.
Redundancy: Failover relies on redundant systems (also called “backup” as in backup plan). The redundant systems are the same type and sometimes are called replicas. This redundancy ensures that if the primary system fails, the secondary system can take over seamlessly.
Automation: Redundancy alone cannot guarantee high availability. Since humans are slow, automation is often used.
Automatic Detection: An automatic fault-detection mechanism observes the primary system to detect failures.
Automatic Switch: When a failure is detected, the failover mechanism kicks in and redirects load or workload to the secondary system. Also switching the load back to the primary when it recovers.
Automated Recovery: Sometimes an automated process is used to recover the primary system using simple techniques. For example: resetting cache, restarting, starting a fresh instance, etc.
Higher Cost: Redundancy and automation increase the resource cost and system complexity (compared to the happy land of 🌈 rainbows and 🦄 unicorns where nothing ever fails). The cost depends on the available technology, type of service, traffic volume and most importantly how the consumers perceive reliability.
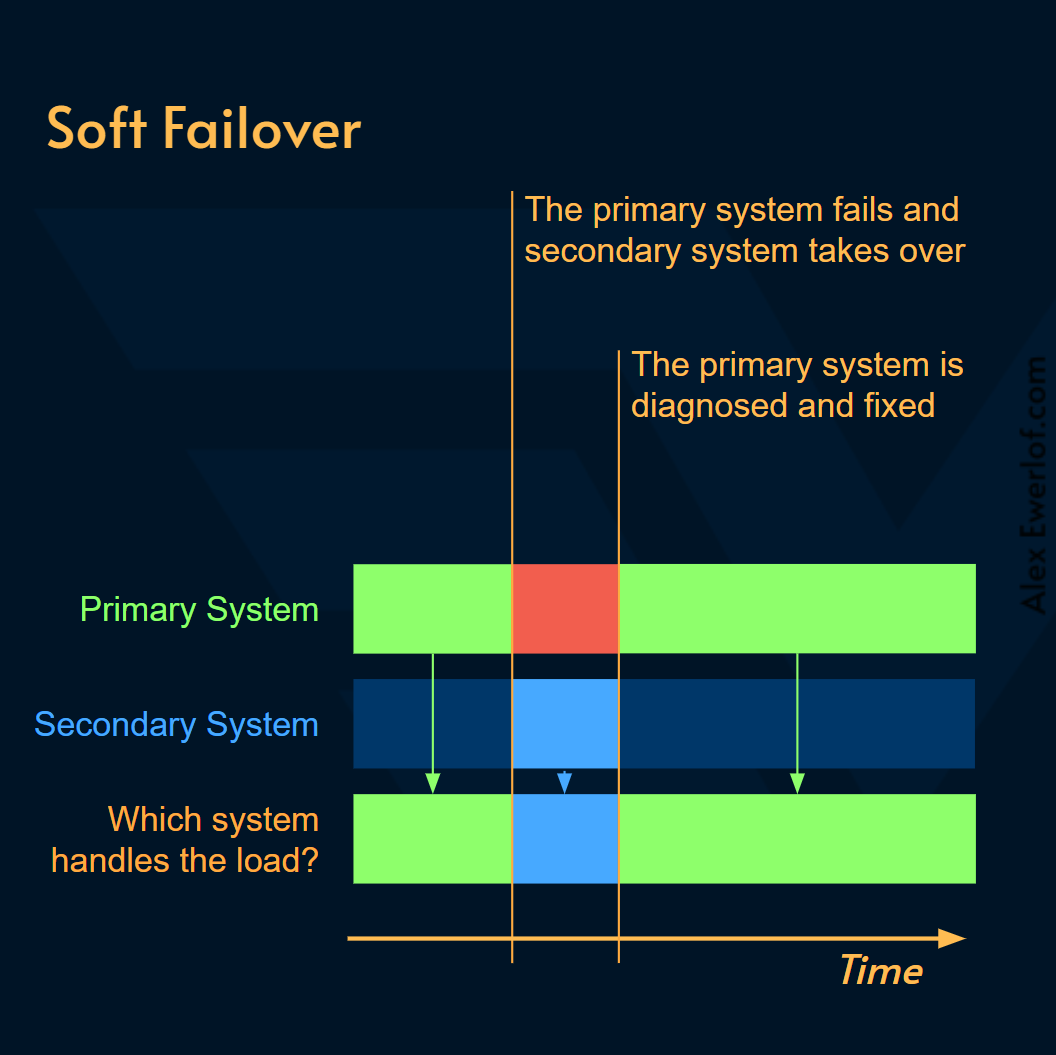
Below is a timeline for how the failures in primary and secondary systems cancel each out to achieve a higher total service level (e.g., Availability).

Types of failover mechanisms
Active-Active/Passive
There are two types of failover mechanisms based on how the primary and secondary systems handle the load:
Active-active failover: both primary and secondary handle the load. This way one of them doesn’t get overloaded while the others are just standing by. This is how most load-balancers work: they distribute the load among similar systems.


Active-passive failover: while the primary is handling the load, the failover system is on standby. This setup is also called Active-standby.


Which one you choose depends on the cost. We’re not just talking about the cost of extra resources. The cost can be anything from complexity to user-facing service levels like higher latency (see the examples below for multi-region failover).
Having an active-active setup also enables cool trickery like improving the latency Service Level objective. For example, you can send the same requests to multiple systems and return the quickest response to the user.

This way the latency of the system as a whole is as fast as the quickest replica.
Hot/Cold
When it is time to switch the load to the secondary system, there are two types of failover mechanisms:
Hot failover: the secondary system is ready to handle the load immediately. The active-active setup is always hot, but you may have a multi-cloud setup where Google Cloud can take over in case AWS fails. OK bad example! Who does that? 😄A better example is when the secondary system does not get any load to reduce the cost, but it has a couple of nodes running just in case. When the load shifts to the secondary, it’ll automatically scale to handle the demand.
Cold failover: the secondary system is in standby, or hibernation mode and some work is needed to make it ready to accept the load. For example, new EC2 instances need to spin up or data needs to be synchronized prior to the secondary system being able to handle the load.
The main difference between the two is the time it takes till the secondary system can take over the load and how much it impacts the perceived reliability from the consumer point of view:

Cold failover hurts the service continuity, but it is often cheaper to implement. Sometimes a small increase in reliability can have a high cost in engineering but it is worth it as demonstrated by Project Nimble at Netflix.
Hard/Soft
And when it comes to what happens to the primary system upon failure, there are two types of failover mechanisms:
Hard failover: kills the primary system. This is a rather extreme measure that should be weighed against the cost of recreating the primary system. Sometimes the best option is the good old IT solution to all problems: “have you tried turning it off and on again”? 😄This solution is less suitable for stateful systems like databases or message queues.

Soft failover: leaves the primary system alone so you can diagnose and fix the problem. This is also called graceful failover and can be done proactively before it is too late to save the system from permanent failure. (src: Couchbase)


Failover Examples
A few years ago, I was working with a service running on AWS that had a high availability SLO (Service Level Objective).
Most of the customers were in Scandinavia, so we served the bulk of the traffic from eu-north-1 region based in Stockholm, Sweden.
But we also ran the same setup in Ireland in case our services failed in Stockholm. This was a hot failover. The Irish servers were ready to take over, but we had configured our AWS Route 53 to prefer Stockholm. When our service failed in Stockholm, we would shift the load to Ireland to guarantee a high availability towards the end users.

Using Ireland, however, wasn’t ideal because it would increase the latency. That is because our service had a dependency that could still run in Stockholm. In that case, the user requests would go to Ireland, Ireland would fetch data from Stockholm and then returned the result.

It would be ideal if our dependency were also available in Ireland, but we didn’t have control over the failover mechanism of that system, neither was the cost justified for the team responsible for our dependency. Our dependency was a stateful service and having a multi-region strategy would imply database replication. Our service didn’t justify the cost of resources and complexity.
The higher latency was an accepted cost in our case, but we preferred to serve the traffic from Stockholm. Hence the active-passive setup.
Other examples
A good example of the active-active setup is Amazon Simple Queue Service. It stores all message queues and messages within a single region but with multiple redundant Availability Zones (AZs). That way if a single availability zone goes down (for example in case of natural disasters), another availability zone takes over.
The multi-AZ failover strategy is a relatively cheap way to increase service levels. AWS EC2 Auto Scaling groups for example allow a load balancer to distribute the traffic among the instances running across different availability zones in one region with some configuration.
When to use Failover?
High availability is critical: If the system requires minimal to no downtime and demands continuous availability, failover is a good risk mitigation strategy to consider.
Secondary system is feasible: As a general rule of thumb, stateless services are easier to duplicate but when it comes to stateful services (like databases), it is more complex and costly to set up a secondary system. Sometimes a secondary system is not feasible due to requirements or technology at hand: for example, due to GDPR the data is not allowed to leave EU borders, but the only available options are in the US or China.
The cost of mitigation is reasonable: This should be obvious based on what we discussed so far, but it’s important to avoid over-engineering the service when the requirement or the profit don’t justify a failover mechanism. Sometimes, a risk can be accepted because the mitigation is not worth it.
Conclusion
Failover is a risk mitigation strategy that aims to improve service continuity through redundancy and automation.
Failover is usually more expensive than the other alternatives. This follow up article digs into fallbacks as a more affordable alternative.
This article took about 10 hours to research, draft, edit and illustrate. If you enjoy it, you could support my work by sparing a few bucks on a paid subscription. You get 20% off via this link. Thanks in advance. 🙌