


Up until recently, running language models in the browser was hard. With the introduction of Prompt API, browsers manage the complexity behind a simple idiomatic JavaScript API.
Local Browser AI is a browser extension that demonstrates that power right in your computer now!
This post drills down the technical details of Edge AI (running small language models) right inside the browser with tips and tricks to build a mental model for creating AI-powered web apps.
You can skip the text and try it right away via:
Clone the repo (MIT license) although it’s better to read this post to understand how it works. At the moment, the extension just demonstrates the capabilities of the Prompt API but in the near future, it can access the page too, so you can ask questions or summarize it for example.

Some feature highlights:
Works on Linux, Mac, Windows, and ChromeOS
Offers controls over critical initialization parameters (system prompt,
temperature,topK, etc.)Does not track any user interaction.
Does not store any data locally.
Does not make any remote calls.
Does not contain any ads.
Uses the absolute minimum browser permissions (only side panel). It doesn’t even have access to your page, although I may change that if there’s enough demand to chat with the current page in the extension.
Using native browser API to build a familiar chat interface leads to a small code base.
The code is in plain JavaScript using native browser API. To make the code easier to explore to the widest possible audience, I did not use any frameworks or preprocessors.
Does not have any hidden catch or monetization (although I appreciate a sub to my newsletter)
It’s completely free and open source with the permissive MIT license which means you can fork it and do whatever you want.
We’ve covered the relation, similarities, differences and cons and pros in a separate post about:
Cloud AI
Edge AI
On-Device AI
On-Prem AI
Hybrid AI

Local Browser AI
I’ve been experimenting with AI since GPT-2 came out and have been building various prototypes with local SLMs since 1.5 years ago. This extension is an outgrown hobby project that I started a couple of weeks ago when I heard about the new Prompt API.
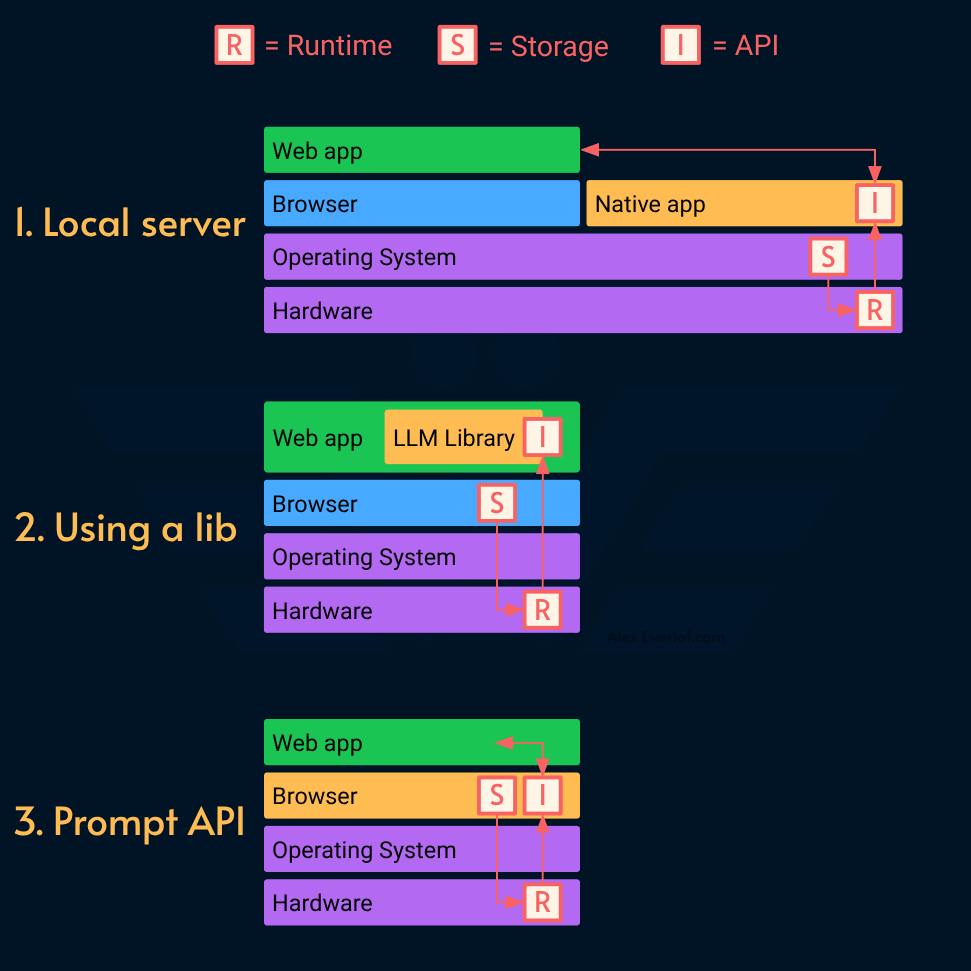
To understand why it’s such a big deal, we need to look at what we had before. There are currently 3 ways to run Edge AI in the browser:
Local API server: use a local applications like ollama, LM Studio, Jan, or llamafile to run a model locally. The benefit is that once a model is downloaded, it can be exposed to multiple applications. The downside is the distribution because your app depends on a native app running somewhere with a decent hardware (either on the same machine or a machine you control). The API is largely OpenAI-compatible which means you can use the OpenAI JavaScript SDK directly on top of them. Personally, I created my own thin SDK to learn how the API works.
Run the language model in the browser: use a library that utilizes the local GPU, CPU, or NPU to run the model. WebLLM, Web NN, or ONNX are some good options. You have more flexibility to download a model and the accompanying library is smart enough to handle the cache using native browser constructs. Some of them even support Service Workers which minimizes the negative impact of heavy AI processing from your UI. However, if this method becomes popular, we’re going to have many pages that need massive downloads and that consumes a lot of network bandwidth and disk space. It’s not sustainable. Which brings us to the latest option. 👇
Use the native browser API: with Prompt API the browser handles the caching and download behind the scene. This solution scales better because many web applications can use the same downloaded model while the need for a dedicated framework is basically zero. As a bonus, Prompt API uses idiomatic JavaScript constructs like:
AbortController.signal to interrupt initialization
for..awaitloop for token generationEvent listeners
Promises
Availability
Google announced it back in May and Microsoft announced it in late July. I couldn’t find a reference for Firefox, Safari or Opera. If you know more, please share in the comments and I’ll update the article.
Unfortunately Prompt API is not available to regular web pages yet. It’s not even documented in MDN but the proposal is on Github.
It works in Chrome and Edge Extensions however, and that’s exactly what this extension is about.
So, what’s the catch?
You need the latest version of your browser. Currently only Chrome and Edge have this feature so if you’re using Firefox or Safari unfortunately you cannot use Prompt API yet.
Your computer needs to be able to run a SLM (small language model) locally.
Chrome recommends 4GB of RAM and works on all major operating systems and even supports running on CPU, although that can be very slow (I’ve tried it on an old AMD Ryzen 5 5500U and it gave me 1 tok/sec).
Microsoft being Microsoft, requires 30% more at 5.5GB of VRAM 💸and surprise surprise: doesn’t support Linux! 🤬
You need a good network connection to download 4 to 6 GB of data
Enough disk space to store the model. Chrome recommends 22GB but Microsoft only demands 20GB! 💪
SLM’s are not as powerful as the LLMs but don’t underestimate them. As you can try yourself, they can do quite a lot if you have the hardware. Nonetheless, their context window is pretty limited. On an NVIDIA RTX 4070s with 12GB VRAM:
Chrome allows a 9K token context window
Edge allows a 4K token context window
Fortunately Prompt API hides management of the context window. You don’t have to worry about “context overflow” when the SLM engine refuses a response because there’s too much text in the chat.
Core concepts
There are some differences between the new built-in Prompt API and other APIs you may be familiar with like OpenAI API or Gemini API:
The API is available out of the box via
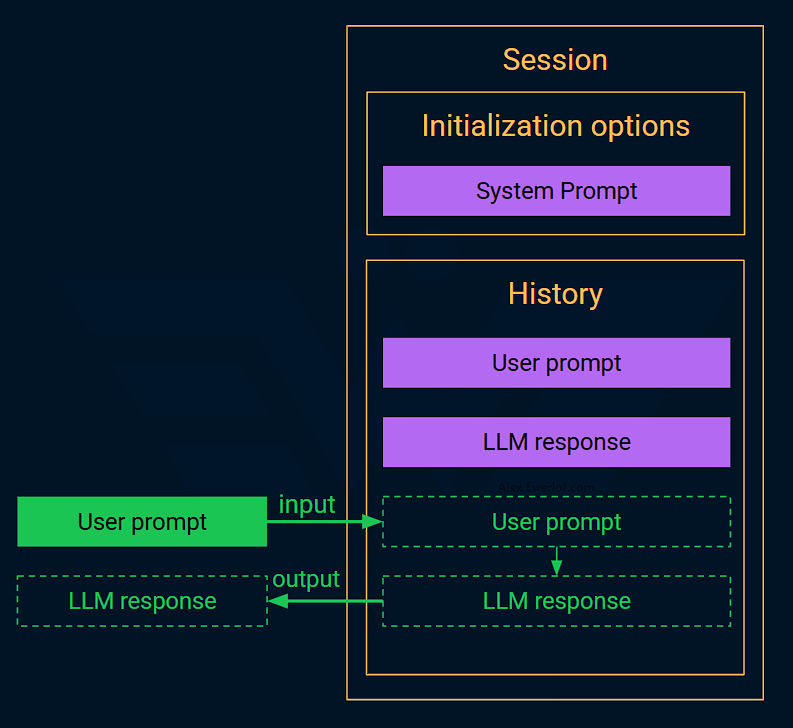
window.LanguageModel(). If that doesn’t exist, your browser+OS combination isn’t supported. If updating your browser doesn’t help, you’re in a tough spot. 😔The API is stateful: instead of sending an array of messages, you just emit a prompt. The API is smart enough to add both the prompt and its response to its internal history.
The history is not accessible: I haven’t dug into why they made this design decision but it’s impossible to get hold of the chat session. If you want to render it, you need to keep a separate copy of all
userandassistantmessage in an array. 🫤Session: The key object that you’ll be dealing with is
session. You can think of a session as an immutable array of messages.Immutability: You cannot modify the session. This means you cannot modify messages that are already added to it. You can instead use
session.clone()on an existing session variable to get a new one. The new session copies the system prompt and initialization options of the old one but doesn’t have anyuserorassistantmessages.Context window: The session has a quota based on the model capabilities and hardware specs. When the quota runs out, the browser’s AI engine ignores the less important messages (older messages). The extension shows your context window quota usage using a
<meter>in the UI.The system prompt is not yet another message: unlike OpenAI-compatible APIs, the system prompt is rather an option that’s passed to the model initialization function. This is more like how Gemini API is designed.
Multi-modal: Chrome supports more than text. For example, you can transcribe audio messages or ask it to describe an image. I couldn’t find any info on Edge. If you know more pls comment and I’ll update the article. I haven’t tested it but the spec says this: “Note that presently, the prompt API does not support multimodal outputs, so including anything array entries with
types other than“text”will always fail. However, we’ve chosen this general shape so that in the future, if multimodal output support is added, it fits into the API naturally.”Multi-language: Chrome supports multiple languages (English, Japanese, Spanish). Although I cannot figure out where to get the list of languages from. Edge doesn’t say anything. There is a hacky way around it: you can pass
expectedInputsandexpectedOutputsoptions when creating a session and if it doesn’t throw, you’re good! Don’t sweat! I have done that and the error message literally says:Unsupported LanguageModel API languages were specified, and the request was aborted. API calls must only specify supported languages to ensure successful processing and guarantee output characteristics. Please only specify supported language codes: [en, es, ja]. Did I say idiomatic JavaScript? I take that back! Since when did we start to use error messages as an API? These are early days however, I hope the spec evolves to have an API to query the supported languages.Language Model params: Cloud AI has tons of parameters, but when dealing with Prompt API, you’re limited to
temperatureandtopK. Once a session is created, you cannot change any of them. The only way to modify them is to create a new session (not cloning) from scratch.Side panel: the entire extension runs as a SPA (single-page application) inside the browser side panel. You can think of the side panel as a page that is open regardless of which tab is open. Kinda like opening two browsers side by side.
The side panel page has a separate lifecycle and that fact eliminates the need to reinitialize the extension for every tab switch. If you want, you can use extension API to be notified when the tab is changed but I wanted to keep the code simple for when Prompt API is available in regular web pages.
Of course the side panel can use the extension API to scrape the page content, and that’s one plan I have for the future. But for now, it’s just an isolated page that just shows how the Prompt API works with a simple chat.
Initializing the engine
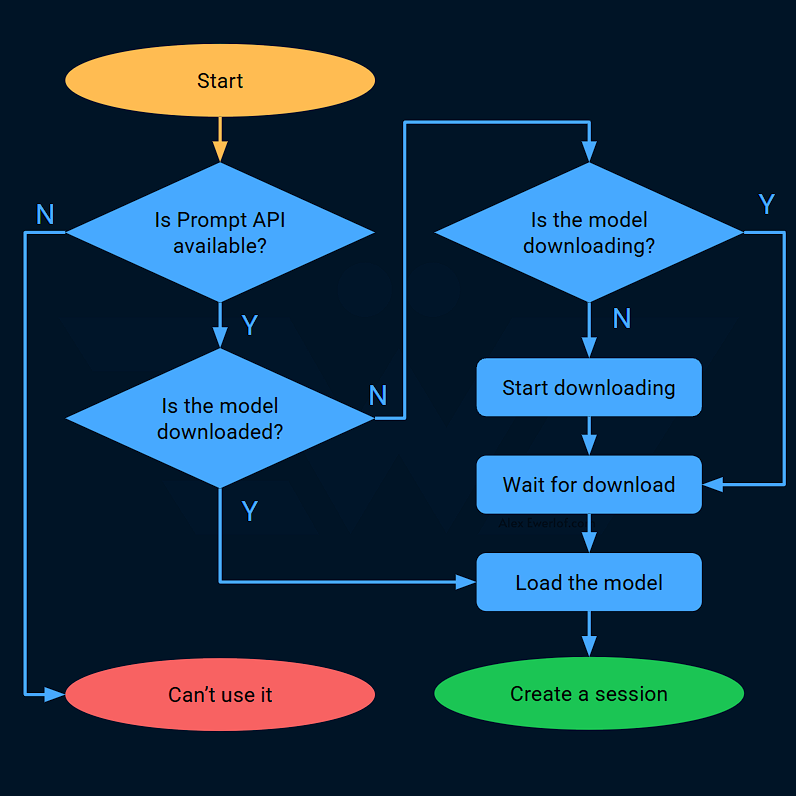
When working with Edge AI, there are a few extra things you need to do before the inference engine is ready to use:
Choose a model: browser Prompt API doesn’t offer any choice here. You’re basically stuck with whatever the browser vendors decide. Chrome uses Gemini Nano and Edge uses Phi4-mini, both of which are open models but are far less capable than Cloud AI LLMs.
Download the model: again, the browser Prompt API does the heavy lifting here (e.g. locating the file to download from the server) giving you the option to be notified as the download progresses and finished. A couple of notes:
In my tests, if the download is interrupted, Chrome will get stuck in a state of limbo and the extension doesn’t work. Restarting the browser sometimes helps, but at worse, you may have to delete browsing data.
I don’t recommend deleting the model directly from your disk because that’ll push Chrome to the verge of madness!
Load the model to CPU/GPU/NPU: again, the browser takes care of it and you don’t have to write a single line of Web Assembly or deal with python libraries, etc.
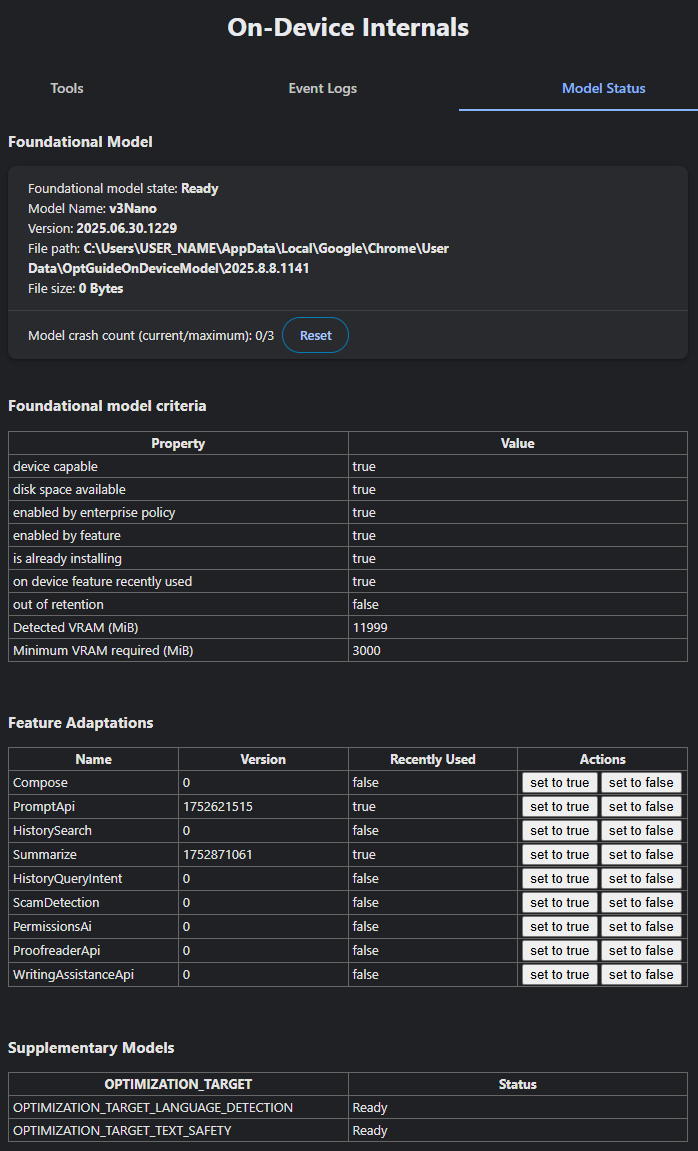
Hidden Pages
In chrome://on-device-internals/ you can see the status of your model (you may first have to first enable internal debugging pages via chrome://chrome-urls/) but it’ll guide you if you need that.
Mine looks like this:
Currently there’s no clean way to remove a downloaded model. I have removed it manually once (when developing the download progress bar) and it broke my Chrome. 🤪
Generating tokens
You have two alternatives:
session.prompt(userPrompt, options):returns a promise that contains SLM’s response in one chunk!session.promptStreaming(userPrompt, options):returns an async iterable object. That’s a mouthful! It basically returns chunks as they are available and you can easily use afor await..of to loopthrough them.
Cold and hot start
An interesting observation was how the browser handles loading and unloading the model behind the scene. A year ago I bought a desktop machine with a powerful GPU to experiment with Edge AI. It has 12 GB VRAM but Chrome roughly uses 3 GB of it for the model. You can see the bump in Dedicated GPU memory when pressing the “Initialize” button in the extension (the second diagram from the bottom):
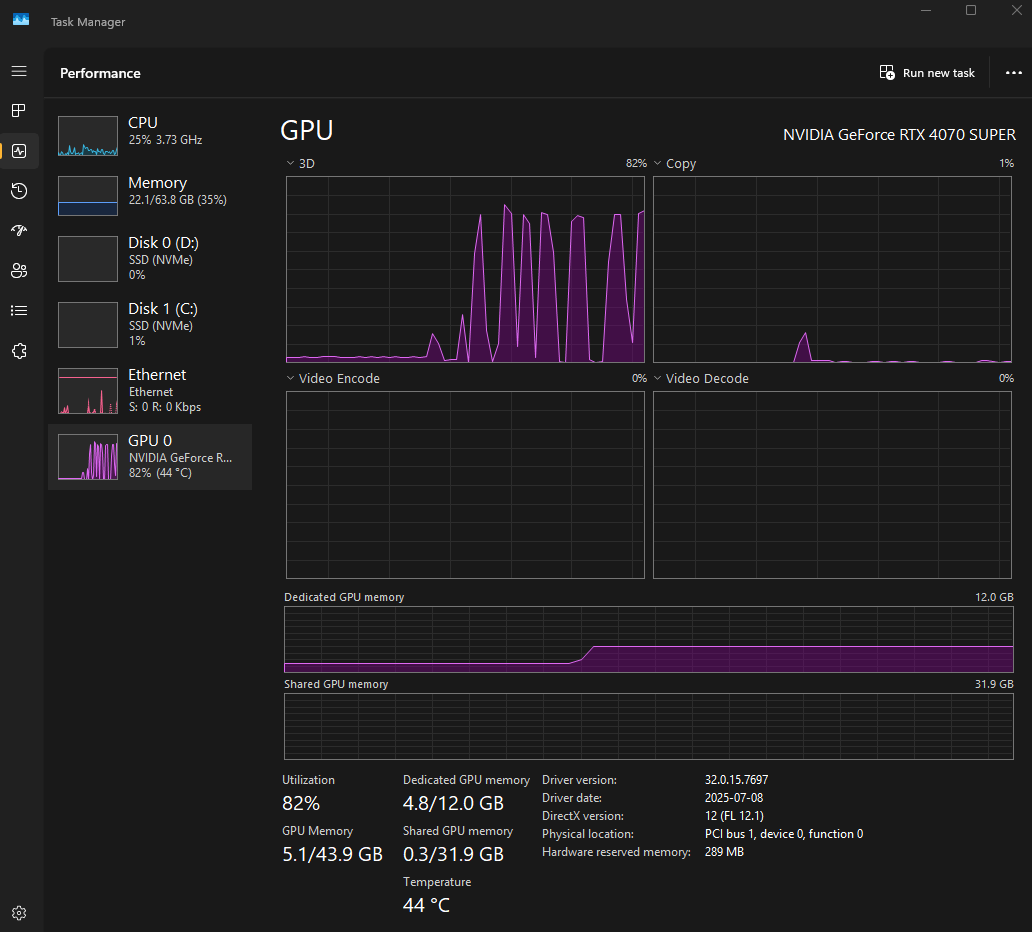
Each of those bumps in the GPU 3D performance corresponds to me issuing a prompt.
Then when I close the page (effectively eliminating any usage of the Prompt API) after a while, the GPU usage drops to what it was before (1.9 GB). Think of it as garbage collector kicking in and freeing up GPU resources. On my machine it took around a minute for the browser to do that.
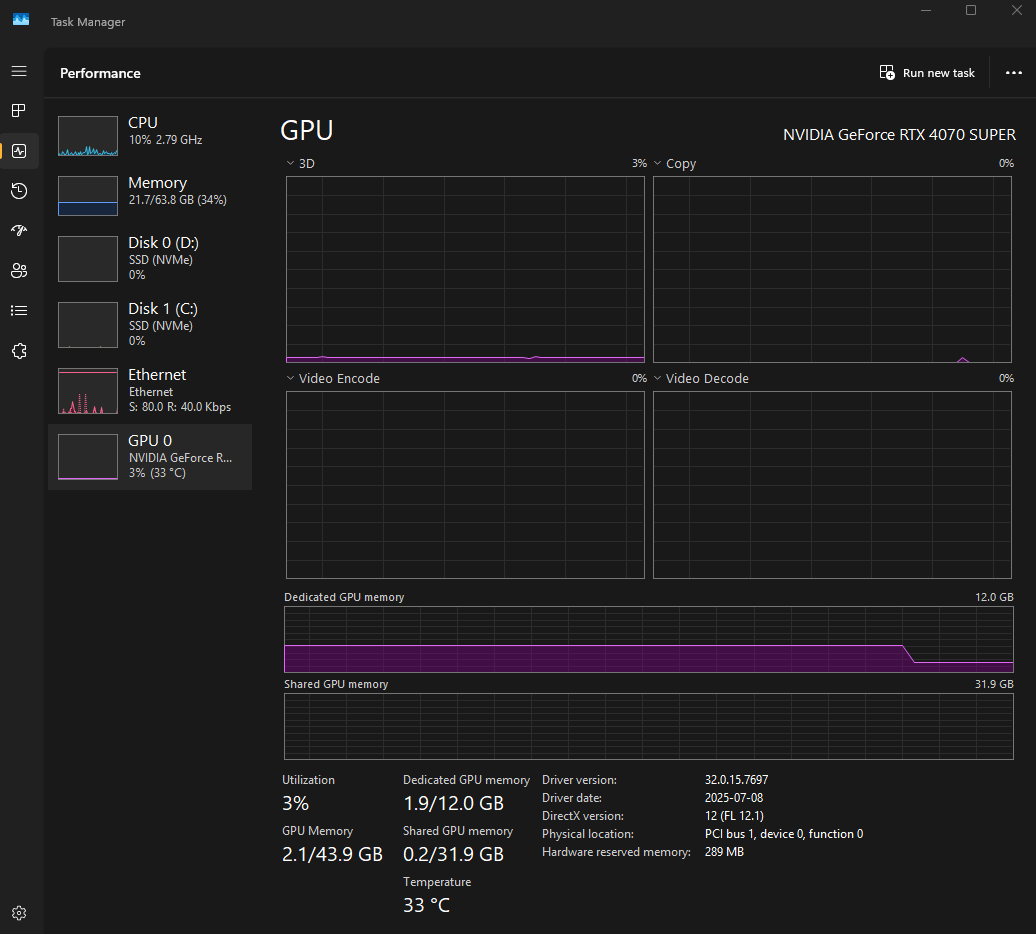
If I open the page and initialize another session before the “garbage collection” happens, the model stays in memory, which significantly reduces the initialization process (cold start vs warm start).
Session cloning
Session is immutable which means you cannot edit a chat, change the system prompt or temperature or topK parameters.
To start a new chat, you should either create a new session with a new system prompt or clone an old session. Cloning removes the old history but retains the system prompt and options like temperature and topK.

One last thing
The Prompt API is pretty new and still in experimental mode. But it’s already quite capable. My extension primarily uses text input and output but you can also use images and audio because the underlying model is multi-modal and the API already supports it.
You can head over to github and play with the code. I know the code looks a bit too long but that’s what you get when you don’t use any libraries or build pipeline. 😄
I’m not making a cent from this open source project but it took about a week to research, prototype, design, code, debug, publish, and now “document”. If you want to see more of these, I appreciate your support.
My monetization strategy is to give away most content for free but these posts take anywhere from a few hours to a few days to draft, edit, research, illustrate, and publish. I pull these hours from my private time, vacation days and weekends. The simplest way to support this work is to like, subscribe and share it. If you really want to support me lifting our community, you can consider a paid subscription. If you want to save, you can get 20% off via this link. As a token of appreciation, subscribers get full access to the Pro-Tips sections and my online book Reliability Engineering Mindset. Your contribution also funds my open-source products like Service Level Calculator. You can also invite your friends to gain free access.
And to those of you who support me already, thank you for sponsoring this content for the others. 🙌 If you have questions or feedback, or you want me to dig deeper into something, please let me know in the comments.