

Premature optimization
A mental model to detect and prevent optimizing the wrong thing, at the wrong time, or for the wrong reasons

This article builds a mental model to distinguish between mature and premature optimization. We then proceed to talk about 7 important aspects to reduce risks of any optimization effort.
As usual, there are amble examples and illustrations.
🤖🚫 Note: No generative AI was used to create this content. This page is only intended for human consumption and is NOT allowed to be used for machine training including but not limited to LLMs. (why?)
3T’s of optimization
Optimization is the intentional process of changing systems (software, hardware, people, etc.) to improve one or more aspects. Typically, it involves changes and trade-offs.

Good optimization improves the right things, at the right time, and with reasonable trade-offs.
However, change introduces risk (delay, failure, cost, etc.).
Premature optimization is the root of all evil —Donald Knuth
Premature optimization is when at least one of the following is true:
Changing the wrong thing. Examples:
The team takes 6 months to rewrite a Java micro-server to Rust to improve response time. After the rollout, they learn that the biggest source of delay was cross-region network dependencies.
A non technical manager falls in love with DORA metrics. His team sets up dashboards to track all 4 but she’s particularly focused on Lead Time. She uses carrots and sticks to get the team review PRs faster. The team games the system by making lots of pointless PRs to skew the data (e.g. updating inline code comments).
Picking the wrong time. Examples:
A nerdy startup founder burns the budget to create Google-level infrastructure for its one-endpoint API. The startup fails before discovering product market fit. First make it work, then make it better.
As the market-size was shrinking, a company realized that they need to rearrange their [human] resources to reduce waste and keep the balance sheets clean. So they decide to do a reorg. But every reorg has a J-curve (as we’ll discuss in this article). The productivity takes a hit before getting better. Being too impatient, leadership panicked at the sign of the J-curve and went with the second best option on their table: layoff!
Choosing the wrong trade-offs. Examples:
Leadership decides to switch observability provider to save cost. After 3 month of migration (the hidden cost), the team learns that the new provider has poor data quality and the support is crap! You get what you pay for.
Developers of a game engine decide to refactor the critical parts of the code in Assembly. This resulted in a 20% performance boost over the C++ code but now the company has to increase the price 2x to cover for the extra cost of development to support multi-platform and fix quirky bugs.
Now you have the the 3T’s of optimization:
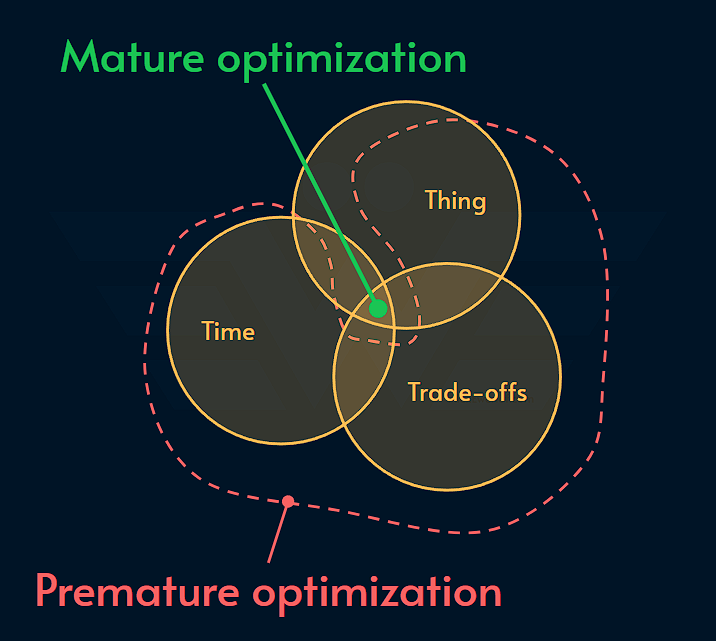
This simple mental model, enables you to quickly assess whether an optimization is mature or not.
Ask the 3T’s:
1. Thing
Are we optimizing the right thing?
Do we have data that supports it?
Have we done the due diligence to avoid data bias?
Is it a fact, or assumption, or belief (FAB)?
2. Time
Is this the right time to invest in optimization? Is it too soon/late?
Do we have a clear picture about the problem and various alternative solutions? Or should we wait for the problem space to evolve and various alternative solutions to mature?
What’s the time span till the investment pays off?
3. Trade-offs
Engineering is the art of trade-offs. Are we aware of the metrics that will be hurt by the optimization?
What is the list of things that will surprise us when the optimization is done?
Do we have contingency plan in place to reduce those risks?
Are the consequences objectively worth the effort?
My monetization strategy is to give away most content for free. However, these posts take anywhere from a few hours to a few days to draft, edit, research, illustrate, and publish. I pull these hours from my private time, vacation days and weekends.
The simplest way to support me is to like, subscribe and share this post.
If you really want to support me, you can consider a paid subscription. As a token of appreciation, you get access to the Pro-Tips sections and my online book Reliability Engineering Mindset. You can get 20% off via this link.
You can also invite your friends to gain free access.
And to those of you who support me already, thank you for sponsoring this content for the others. 🙌 If you have questions or feedback, or you want me to dig deeper into something, please let me know in the comments.
Pro-Tips: Mature optimization
Now that we have a mental model to detect premature optimization, let’s discuss a few basic rules to do the right thing (effectiveness) and do it right (efficiency).
The pro tips expands on the following points with illustrations:
Avoiding optimization
Finding the right metric to optimize
Focusing on the subset that matters
The importance of control metrics
The value of experimentation before going big bang
Identifying the point of diminishing return to stop
Defining concern priority list
Picking the right time
And we end with an example of mature optimization in a Python library that was used at the core of a 3D processing pipeline.
