

Multi-tiered SLOs
How can the same SLI have multiple SLOs? What are the advantages and disadvantages?

SLI (service level indicators) are normalized metrics to measure the reliability of a system and give a focus to data driven optimization. SLO (service level objective) specifies the reliability target.
But there’s no rule that says we need exactly one target. In fact, using multiple targets can be beneficial to maintain a guarantee on a critical threshold while optimizing for a desired threshold.
Example 1: Latency
Let’s say latency is an important reliability metric for a system, with the following SLI:
The proportion of sufficiently fast requests, as measured from the load balancer metrics.
We could define sufficiently fast as:
All requests which their response time is below 400ms.
That’s good.
You look at the historical data and system architecture to set a reasonable objective and end up with 90% for the SLO.
Put together, it means:
90% of all requests to the system should be responded to in less than 400ms.
But what if you want to have a bit more granular control? Let’s say the clients have a request timeout of 850ms and you really don’t want to miss that for the majority of the requests. You want something like this:
99% of all requests to the system should be responded to less than 850ms.
Though not common, a single SLI can have multiple SLOs (service level objectives). You may notice that the definition of sufficiently fast was externalized in the definition of SLI above. That allows us to specify some parameters in the definition of SLO.
Putting it all together, we get this:
SLI:
The proportion of sufficiently fast requests, as measured from the load balancer metrics.
SLO:
90% of requests < 400ms
99% of requests < 850ms
These targets overlap with each other, hence the name multi-tier.

This example is taken directly from Google’s example SLO document.
You can also parameterize any part of SLI to be specified in a multi-tiered SLO. This is different from using valid in the SLI formula to scope the performance optimization.
Example 2: Query segmentation
Let’s say that we have a GraphQL endpoint that is used for a range of queries. As you may know the response time of a GraphQL endpoint highly depends on the type of query.
One idea to guarantee an acceptable response time is to segment the queries by operation type:
SLI:
The latency of the GraphQL endpoint by the operation type.
SLO:
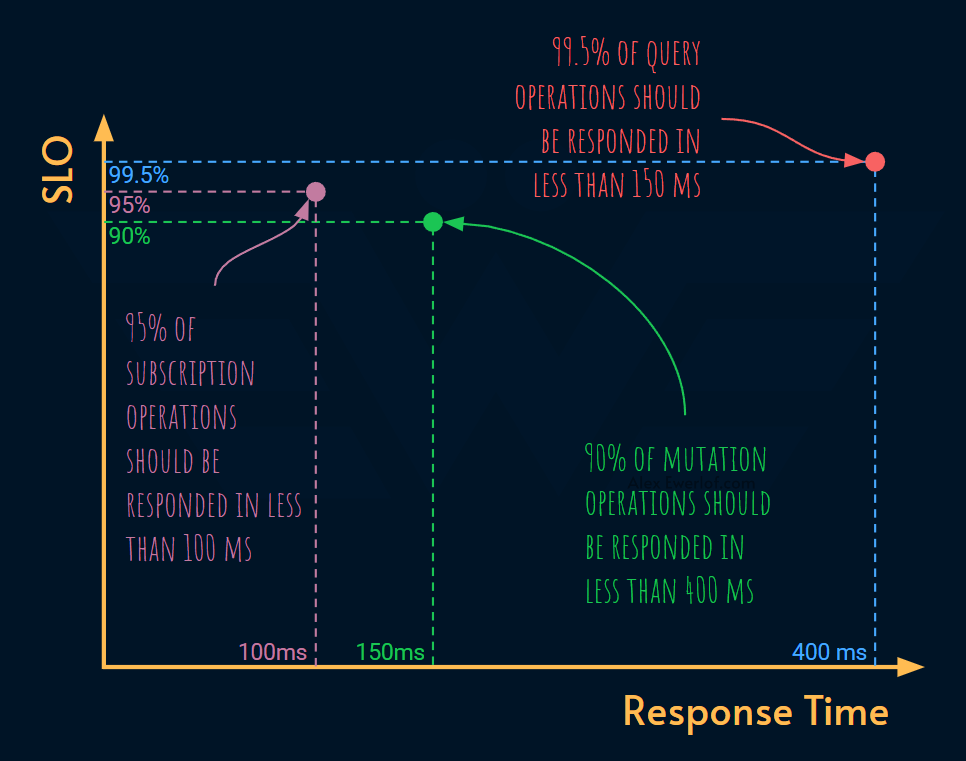
99.5% of query operations should be responded in less than 150ms
90% of mutation operations should be responded in less than 400ms
95% of subscription operations should be responded in less than 100ms
Instead of committing the same response time objective for all sorts of queries, we segmented the commitment into multiple tiers based on the query type:
Example 3: Window
Multi-tier SLOs don’t require a parameterized SLI. You can also parameterize the SLO to have more control over the objective. A useful example is the 🔴window.
For example, if the SLI is uptime, a SLO of 99%, allows for 7 hours and 14 minutes of downtime.
This error budget can be consumed in one chunk or multiple smaller downtimes.

Obviously the longer the outage, the more annoying it will be for the consumers. But there’s nothing in the SLI formula to optimize the distribution of the error budget.
Parameterizing the window allows us to have some control over the incident frequency and length.
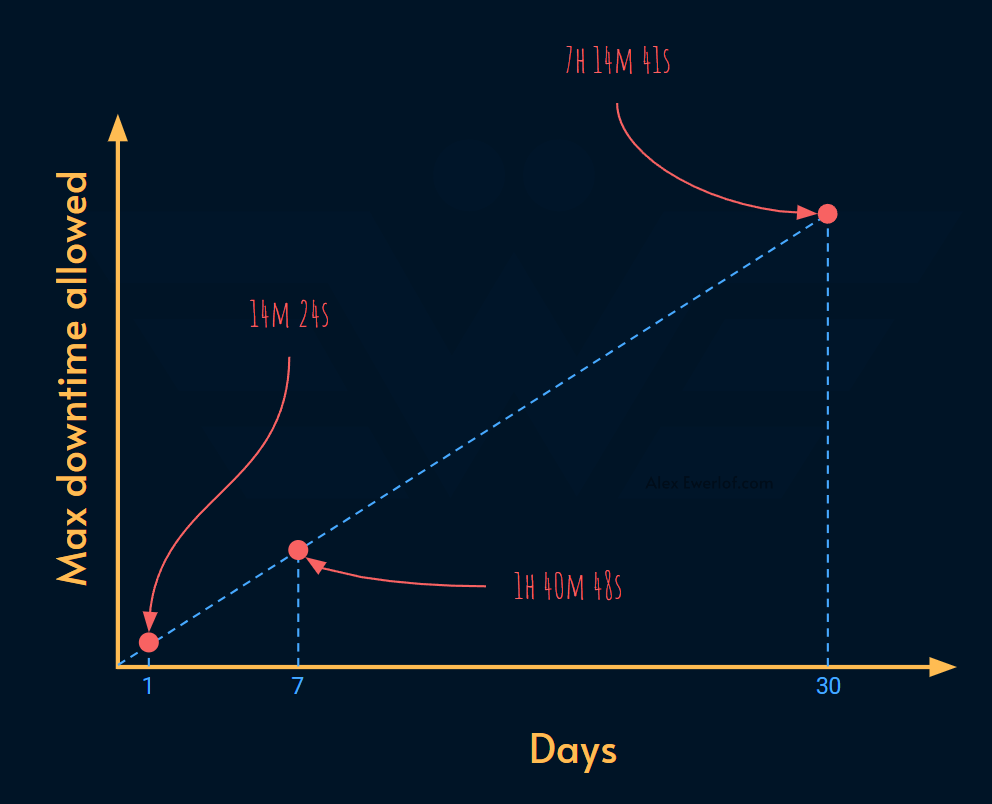
99% uptime, translates to an error budget of:
14m 24s downtime per day
1h 40m 48s downtime per week
7h 14m 41s downtime per month
Depending on what the business and consumers can tolerate, we can define a multi-tier SLO that has the month and week or day (or all 3 of them).
SLI:
Uptime
SLO:
99% in 30 days
99% in 1 days
99% in a day
Please note that these are 3 different SLOs, each of which can be breached individually. But when all SLOs are met, the system hasn’t been down more than 14m and 24 seconds in any given day in the past 7 or 30 days.
You may have different alerting rules for these SLOs. Obviously breaching the 850ms target is more serious than the ambitions of the performance optimization to meet the 400ms threshold.
When to use multi-tier SLOs
As you can see multi-tier SLOs lead to a more complicated setup. The complexity becomes more evident when you’re setting alerts for each of those SLOs. Therefore, adopting multi-tier SLOs should be balanced against its pros and cons.
This post took about 4 hours to research, draft, edit, illustrate, and share. My monetization strategy is to give away the main chunk of the article for free. But for those who spare a few bucks to support my work, I have some pro tips. Right now, you can get 20% off via this link.
