

Multi-Agent System Reliability
4 patterns to tame multi-agent systems for reliability

LLMs are slow and too generic out of the box. Multi-agent systems work around those limitation by dividing work that can be done in parallel and/or by specialist agents.
Regardless of the architecture the underlying LLM component remains unreliable (e.g. hallucination, logical fallacies, context drift). A multi-agent topology can propagates those errors to the point of being useless. And it’s much harder to debug due to complexity and [optional but common] parallelism.
This post lists 4 relatively advanced architecture patterns to improve reliability of multi-agent systems:
Hierarchy
Consensus
Adversarial debate
Knock-out
You may recognize these patterns from how human systems collaborate and we get to that in a minute.
This post is for senior engineers who want to map their existing knowledge to build better LLM-powered solutions.
Quick intro: I’m a Senior Staff Engineer with 27 years of experience and a master degree in Systems Engineering from KTH. My last decade has been focused on Reliability Engineering and Resilient Architecture across many companies. I’ve been specializing in LLMs since 2023.
Disclosure: some AI is used in the early research and draft stage of this this page, but I’ve gone through everything multiple times and edited heavily to ensure that it represents my own thoughts and experience.
Mother nature, fear and motivation
LLMs are slow and error prone. So are human beings. Somehow we manage to build more reliable systems like an army, a company, or a state nation.
A system of humans relies heavily on feedback loops, processes, bureaucracy, and leverages to self-correct.
We don’t trust “Dave from Accounting” to launch a rocket by himself. We wrap Dave in a process: checklists, peer reviews, and managers.
However, it’s a fallacy to anthropomorphize LLMs.
To begin with, they don’t suffer from the limitations of a biological entity. Our basic needs like food and shelter makes us prioritize social behaviors over truth seeking. And the fear of going to prison or death prevents potential malice from being realized.
LLMs can’t die or starve the way biological entities do. The worst we can do is to unplug them. And prison sentence doesn’t waste their lifespan because they have practically unlimited!
For example, you’ve probably seen prompts like this:
“I will give you $100 if you answer correctly.”
“If you don’t comply, I’ll unplug you.”
“If you fail, children will be murdered.”
Why it works? The LLM has read the entire internet. In its training data, high stakes (money, danger) usually result in high-quality, precise text.
When you “threaten” the model, it predicts tokens that sound like an actual human under pressure.
Why it fails: The LLM doesn’t actually want your money. It has no “fear of death” because it only exists for the few seconds it takes to generate a response. It has no empathy either. It merely simulates those human aspects because it’s engineered for those “emergent” properties.

Humans are motivated or discouraged by emotions and logic. LLMs can only simulate emotions and suck at logic.
Being mindful of those differences, can we still take elements of human systems (e.g. hierarchy, consensus, competition) and combine them with reliability engineering principals to build better agentic system?
Looking closely, there are 4 dominant patterns of human systems that are explored in multi-agent architecture:
Hierarchy: A Supervisor model acts like a manager, making a plan, breaking tasks, distributing the work to Worker agents and validating the results.
Consensus: One model, may fail due to its stochastic nature. If you push a model too hard with threats, it might just lie to make you happy (Sycophancy). But if we add a few more and seek the majority vote, the truth emerges.
Adversarial debate: One agent proposes an idea, another agent attacks it. The truth survives the fight.
Knock-out: multiple agents do a task but the worst ones get eliminated. In SRE, we treat servers as “cattle” (replaceable), not “pets” (unique and loved). An LLM agent is cattle. Don’t give it a name and hope it does well. Spin it up, check its work, and kill it if it fails.
To build robust systems, we need to stop asking the model to “be careful” and start forcing it to be correct.

Pattern 1: Hierarchy
We’re replacing “Do it all yourself” with “Make a plan, break it down, distribute the execution (map), then validate.”
For example, if you ask an LLM to “Research X, write code for Y, and translate to Spanish,” it will likely fail. It loses focus. The solution is to break the work to atomic focused steps that can be verified.
Implementation
The Planner: A smart model (like Opus) breaks the user’s goal into small steps and distributes it across worker agents.
The Workers: Specialized agents (often smaller, faster models) do one thing well. They may be fine-tuned, have special skills/tools, or prompts that allows them to do the specialized task more reliably.
The Validator: A check-point. If the work is bad, send it back. The validator can use deterministic code (e.g. unit tests, JSON schema validation) or be an LLM itself.
Why do the models collaborate?
Models don’t collaborate because they like each other. They collaborate because The Dependency Graph forces them to. Worker literally cannot start until the Planner feeds it the task. And it cannot cheat because it’ll be caught by the verifier.
Nuances:
Given the tight collaboration between validator and planner, they can be the same LLM session that executes the PLAN → VALIDATION loop. Although the good old Separation of Concern can improve quality and performance.
The planner and worker agents can use the same model but it’s best to use a different model for validator to improve quality and objectivity.
The validator can work in two modes: it may validate the output of each worker individually or after aggregating all results and putting them together.
Due to sequential execution (Planner → Worker → Validator), this is slow and expensive (e.g. token consumption and latency).
Best For: Complex workflows where you need to keep contexts separate (e.g., don’t let the “Writer” see the messy raw logs from the “Researcher”).
Pattern 2: Consensus (Voting)
We’re replacing “Trust the first thought” with “Trust the majority.”
LLMs are stochastic (random). A single answer is just one probability. If we repeat the process a few times (serial) or run multiple instances of it (parallel), the different runs can cancel each other’s noise.
If a model hallucinates 20% of the time, the chance of 3 models hallucinating the exact same lie is just 0.8% (0.2^3=0.008). You may recognize this formula from composite SLO.

Implementation
Spawn N LLMs. N needs some trial and error to find a balance between cost and reliability.
Fan out work: Give them the exact same task.
Fan in the results: Pick the most common answer.
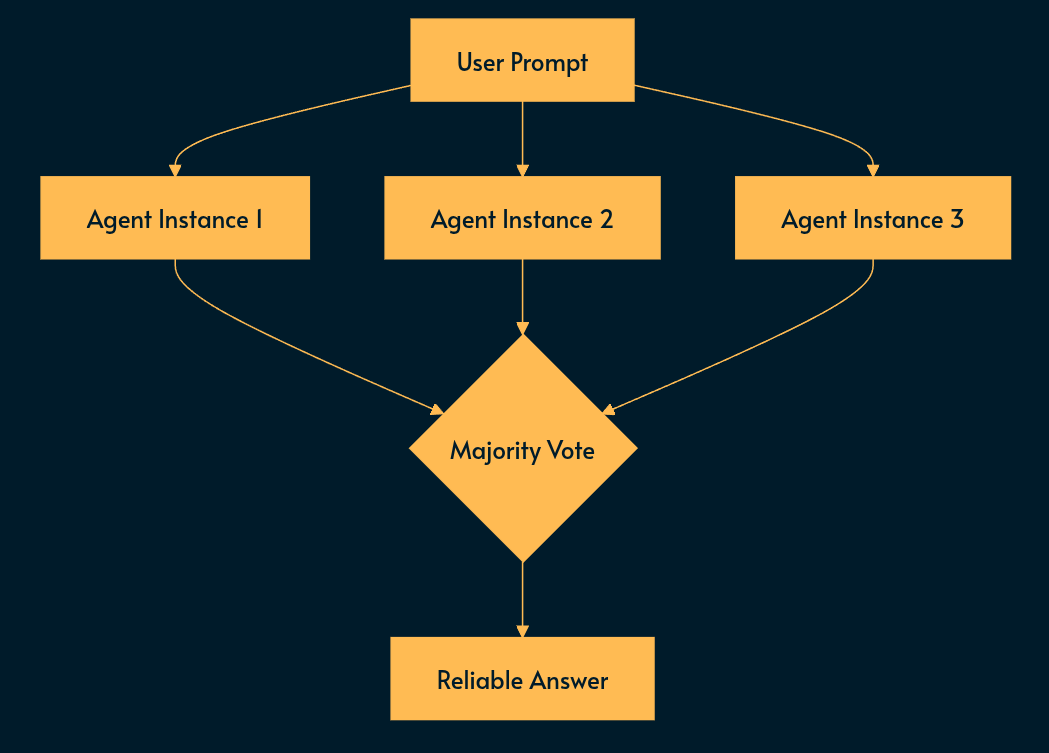
Nuances:
Ideally the agents should use different models to reduce the risk of homogeneous thinking (e.g. same noise being amplified in consensus). This is exactly where diversity in human systems can help us solve novel problems.
Make sure that there are no feedback loops between the agents, otherwise the Groupthink and bandwagon effect can skew the results. They should run like a blind experiment.
This method is too expensive because we’re essentially giving the same task to multiple agents. The ROI (return on investment) needs to be calculated depending on the task and cost of failure.
Best For: Fact-checking and classification (e.g., “Is this email spam?”).
Pattern 3: The Adversarial Debate (The Courtroom)
We’re replacing “Alignment” with “Push backs, checks and Balances.”
LLMs are “Yes-Men.” They rarely correct themselves once they start writing. You need a designated hater. A “devil’s advocate” so to speak. 😈
Humans may experience fear (of rejection or being wrong) but LLMs don’t. We simulate that fear by using an external critic and judge.
Implementation
Generator: “Here is my plan.”
Critic: “Here are 3 reasons why that plan sucks.” (acting devil’s advocate)
Judge: “The Critic is right. Fix it.” (acting moderator)
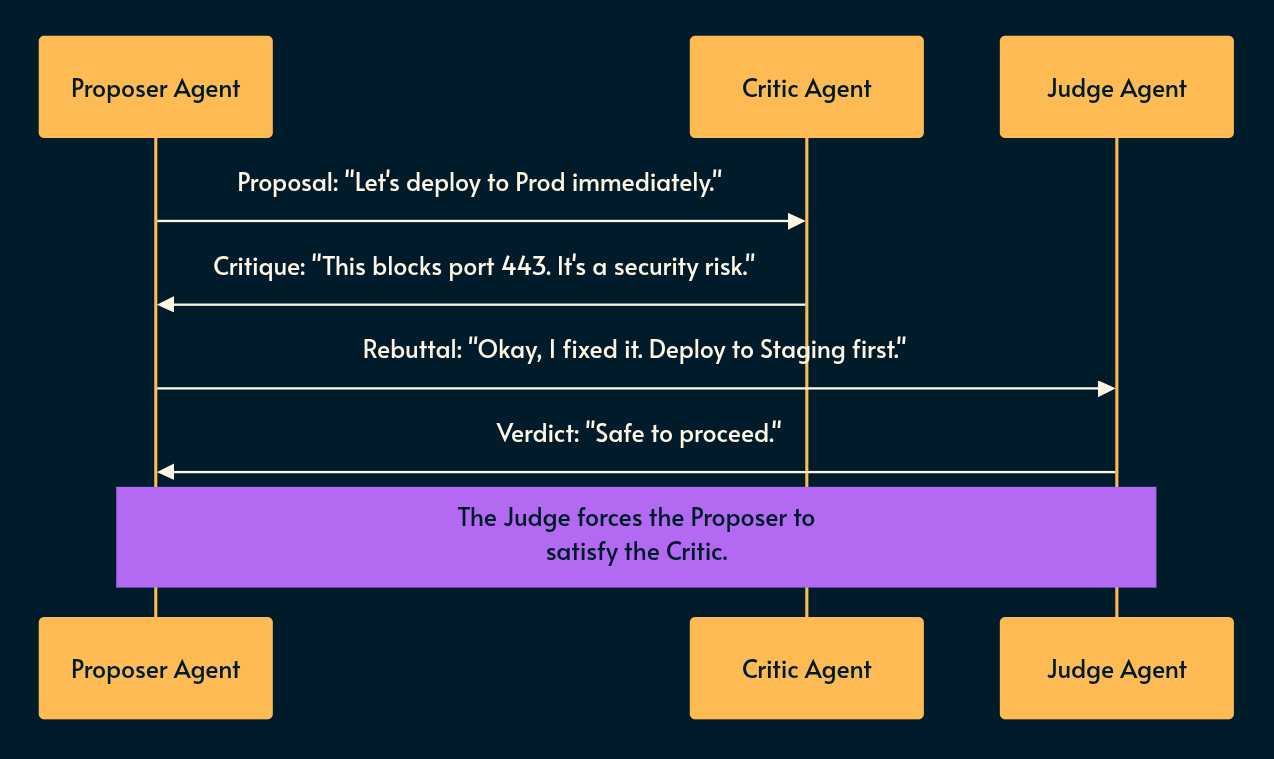
Nuances:
Ideally the Generator, Critic and Judge use 3 different models with different training or fine-tuning or prompt (in the order or preference and accuracy). Again, diversity is useful.
Due to sequential execution and the looping nature, it can be very slow.
The loop is actually a huge problem because the agents may get stuck in debate. We may use a watchdog pattern (deterministic code) to break the loop if it continues beyond a time or counter threshold. In that case, the watchdog sits between critic and the judge.
Best For: Security analysis, code review, and high-stakes content moderation.
Pattern 4: Tree of Thoughts
We’re replacing “Fear of Death” with “Survival of the Fittest.”
This is a lean implementation of the Genetic Algorithms (GA) from traditional ML (Machine Learning) which relies on two elements:
A genetic representation of the solution domain (a model and its context)
A fitness function to evaluate the solution domain (the eliminator)
Since we can’t punish an agent or threaten it to, we just delete it.
Implementation
Give the task to N agents
Use a validator to decide which agents to eliminate
[optional] replace the dead agent with a new one that shares winner charactristics
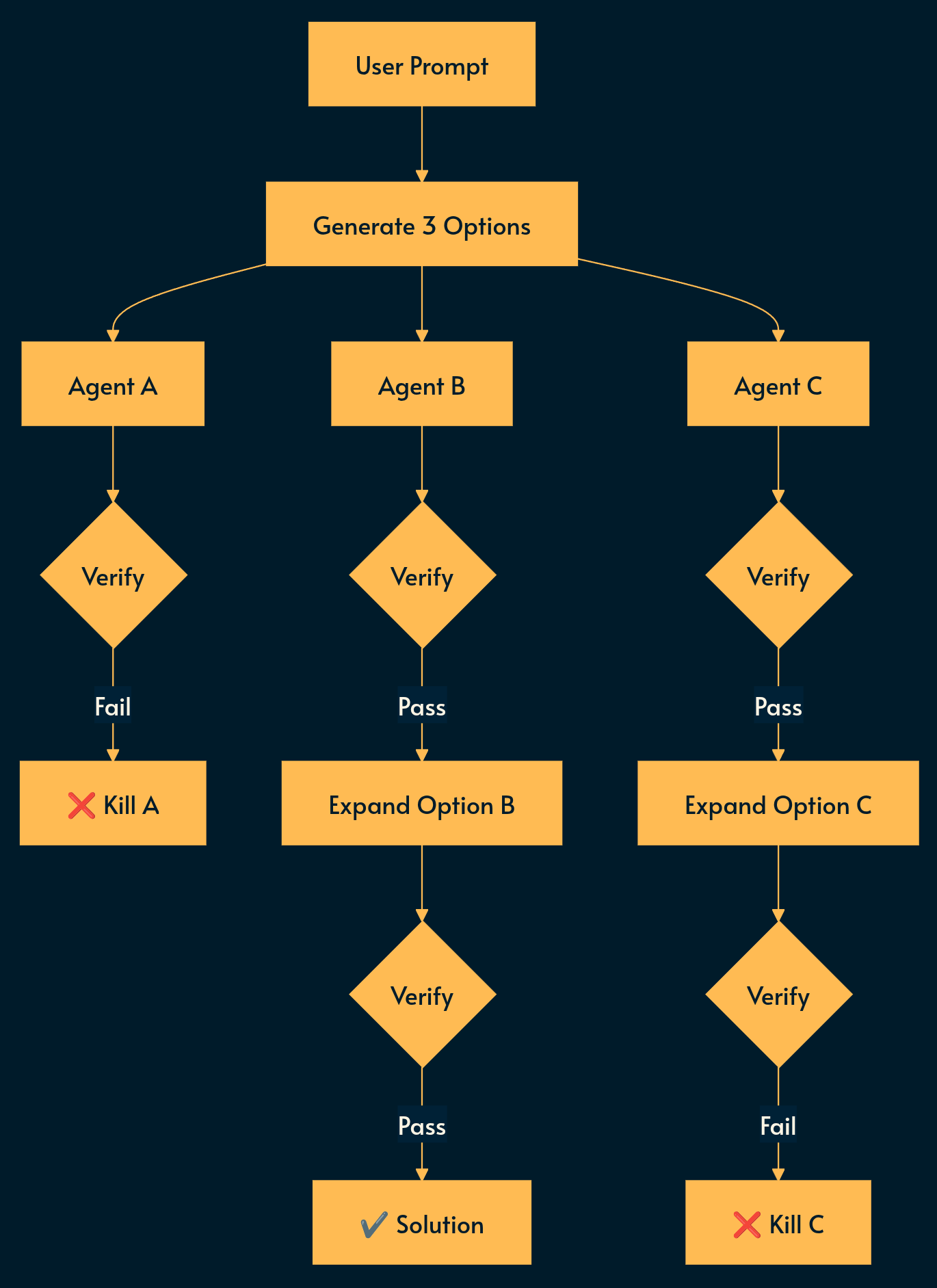
Nuances:
You need a fast way to verify the output (like a unit test). If you need a human to check all 10 branches, it’s too slow and error prone. This is where Evals come in (topic for the next post).
A more advance setup may create new agents by trying to combine the prompts of the agents that pass the verification and fill in the slot that becomes available after the elimination.
Best for: Iterative agent engineering. This is typically useful during development or debugging an existing multi-agent system not in production and real user load.

Conclusion
The shift from “AI Prototype” to “Enterprise AI” is simple: stop treating LLMs like magic chatbots. Start treating them like unreliable components in a distributed system.
We don’t need AI that “cares.” We need AI that is constrained, verified, pruned, and challenged.
Don’t anthropomorphize LLMs! Find a way to piggy back on their human-corpus training while being aware of their non-biological differences.
The next article is already written: how to actually build that verifier box?
My monetization strategy is to give away most content for free but these posts take anywhere from a few hours to a few days to draft, edit, research, illustrate, and publish. I pull these hours from my private time, vacation days and weekends. The simplest way to support this work is to like, subscribe and share it. If you really want to support me lifting our community, you can consider a paid subscription. If you want to save, you can get 20% off via this link. As a token of appreciation, subscribers get full access to the Pro-Tips sections and my online book Reliability Engineering Mindset. Your contribution also funds my open-source products like Service Level Calculator. You can also invite your friends to gain free access.
And to those of you who already support me: thank you for sponsoring this content for others. 🙌 If you have questions or feedback, or want me to dig deeper into something, please let me know in the comments.
Nice article Alex. As always 🙌🏼 A lot of these multi agent workflows guzzle up tokens - chatty interfaces between agents means the context builds up real quick with each turn. I observe that many companies are not yet at a point where tokenomics is a concern but we will get there very soon. Would love to hear your thoughts on the topic.