

When a team is too big
What signs to look for and how to increase productivity with all-round skillset

Lately I’ve been thinking a lot about these questions:
What is a team?
How large is too large and how small is too small?
What qualifies a missions?
How to weigh the cons and pros of specialist vs generalist in the age of GenAI?
There’s a story for several years back that keeps back to my mind. What makes it interesting is the fact that there was no master plan. Yet with a few cultural elements, the story took such an interesting trajectory that it shaped my leadership model. Ever since, I have been an advocate of continuous improvement by preparing the environment instead of being the wise-ass who has the ultimate solution to all problems.
Today I want to tell that story with these key takeaways:
A generalist team is less likely to have internal dependencies acting as bottlenecks, blockage, and single point of failure. Generalist teams are more productive and resilient.
Handovers introduce the risk of misunderstanding, delay, miscommunication, and diluted accountability. Clear ownership requires knowledge, mandate, and responsibility. It’s easier to implement with generalists.
But as we’ll see generalism has its own challenges as well.
🤖🚫 Note: No generative AI was used to create this content (except one image that’s clearly marked). This page is only intended for human consumption and is NOT allowed to be used for machine training including but not limited to LLMs. (why?)
Story
Many yeas ago I was part of a large team. 14 members to be exact.
The problems started from the first standup: I didn't follow 90% of what everyone else was talking about. I thought it's because I'm new to the team but as time passed and I got closer to the other team members I learned that some others feel the same.
It wasn't unusual to see someone visibly yawn or fall almost sleep during the standup. There was at least something in the round of standup that was completely irrelevant and boring to a few.
In an effort to keep the standup short, we had a time limit per person paired with invented hand gestures to signal the person who is talking that their time is over.
We were 11 engineers which can still be fed on 2-pizzas! Size wasn't the issue.
In fact, quite the opposite: every now and then we heard about a task that never came up during the standup and wasn’t in the backlog!
We learned about those phantom tasks as they were close to the finish line or after they ere delivered.
How did that happen? Usually, someone from another team or another part of the organization reached out for a friendly favor and since we had enough bandwidth and great engineers, they often did their best to help.
Async Standup
Later we switch to async standup. The implementation was simple: every workday a Slack reminder would pop up with a fixed message:
What did you do yesterday?
What will you do today?
Are there any impediments or do you need any help?
Each team member would write a comment more or less in line with what they would be telling at a sync (face to face) standup.
Those comments came in during the day, and some folks consistently missed it. Regardless, I rarely read all the comments because they were not relevant to what I was doing.
This was less disruptive than taking 30 minutes (less than 3 minutes per person) for the daily standup, which often dragged to 45 minutes and sometimes even an entire hour!
The async report turned to exactly that: a report.
The main value of a standup is to have a dialogue about blockage and spark opportunities to work together. Otherwise, it's enough to move issues on the Kanban swim lanes with a comment. That covers the reporting part. We missed a dialogue when a dialogue was due.
Concern-based Task Forces
I raised these issue in one of our retrospectives and the EM/PM said they'll take action.
The solution they came up with was to break the team into two halves:
The front-end "task force" (as it was called) would work on front-end stuff basically taking a Figma design and turning it to working UI.
The back-end task force would cover the rest from API, to CI/CD, and configuring cloud and operations.
The idea was to have smaller groups that would move faster, delivery independently, and are more relevant and connected to each other.
And we cut the team by tech, because anyone who has worked with engineers knows that they can be quite religious about their tools of choice. Back-end/Front-end seemed to be different enough to justify that cut.
Good engineers are good problem solvers not a layer of meat wrapped around a tool!
The hypothesis was that front-end developers should care enough about each other's world and standup report. Similarly back-end task force should have some sort of interest and common language to hear each other and collaborate.
As a bonus, now that the task forces were smaller, they could go back to the sync stand up and unlock those dialogues.
This sounded reasonable for exactly 5 working hours! On the next standup it was evident that there are dependencies between the two task forces. Who would have thought? 😄
Regardless, we gave it a go for a couple of sprints until the feedback from the next retrospective came in.
Fluid Task Forces
The next iteration was for people from one task force to attend the standup of the other when they feel it is relevant or they have an agenda to share (e.g. if a front-end person needs to work with the backend person to change the API for a new feature).
The two stand ups where lined up one after the other to facilitate this.
As you can imagine, some of us consistently attended both standups while others consistently took tasks that were in one of the front/back-end bucket.
So the total time spent in standup actually increased while some team members were isolated from each other by the nature of their tasks which was a function of their technical specialty. e.g., one person only worked with our in-house CSS-framework and barely had to talk to the back-end task force.
We were a Swedish team. Efficiency, pragmatism, and continuous improvement was embedded into our culture. I don't say this to brag, but to elaborate why we were in constant endeavor to optimize our work and how leadership supported these experiments.
Individually we were not smart, but together we found a way that was generally more sensible and holistic.
Other solutions
Before discussing the final solution we landed on, I just want to quickly iterate a few other experiments we did:
Break the team in two halves with a shared EM/PM: The API served as a clear abstraction between front-end and backend. But the operation (e.g. CI/CD and even on-call) primarily fell on the back-end team. Unfair.
Create delivery focused ephemeral feature teams: For example, implementing GDPR in the front-end and back-end, required a couple of people from each expertise. Same with the user-tracking feature. These ephemeral feature teams would emerge as needed and collapsed when the task was done. The problem was that it was hard to get the right resources when everyone was locked in some feature team. Maintaining the feature afterwards would unofficially steal resources that were now busy with other tasks.
Hire consultants to cover temporary spikes in bandwidth demand: This was a bit ridiculous because the team was already quite big and it was hard to justify why we need consultants to add extra bandwidth. Upper management pushed back to utilize the available bandwidth in a smarter manner.
By this time, we’re more than a year into these struggles and while some have accepted that this is just the nature of having such a large team, others are still pushing new ideas every retro!
Meanwhile, the company ran out of money to burn (we covered that story before), and as Sundar Pichai says:
Scarcity breeds clarity
The solution: generalists
What worked for us eventually was to remove our specialist hats and be generalists:
Front-end, back-end, QA, DevOps, etc. are all different concerns for the same outcome and impact.
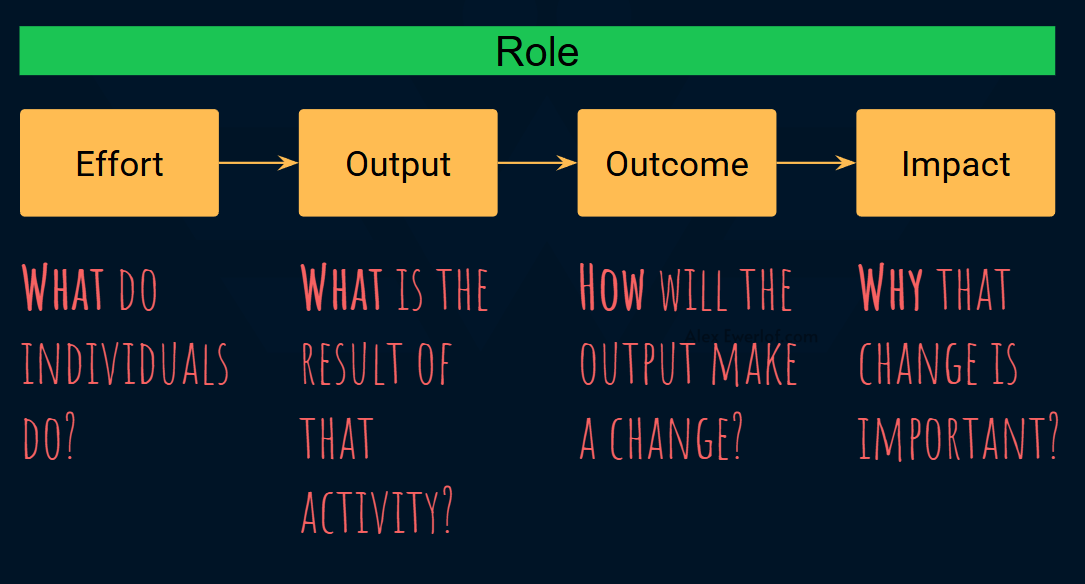
A recent article, dug into why breaking a role into multiple titles is a bad idea that hurts the business (more bottlenecks) and individuals (turning to cogs that only fit special machines).

Sure, learning CSS is a challenge for someone who has spent their entire career behind an API.

Similarly doing cloud configuration had a steep learning curve for someone who makes money moving bit in the browser sandbox.
It is unrealistic to expect everyone to turn specialist over night. The cognitive bandwidth is the bottleneck. It takes time to lean different disciplines especially when you’re new and need to rethink and unlearn.
But with the advent of copilots (with small "c"), it's already easier than ever to build an all-around skillset.
We didn’t have LLMs back then but we had another tool that was even more effective: mob programming! We were fortunate enough to get a department-wide workshop by Woody Zuill who is a recognized force behind popularizing the idea of working together on the same problem.
A huge side effect of mob programming is the knowledge sharing which unleashes the generalists in all of us.
Having worked with both AI-powered copilots and Mob Programming, I still think the latter is more powerful because:
It provides higher communication bandwidth, especially when done onsite
Its self-correction mechanisms of team dynamic prevents problems like hallucination or context limit. Team members are more likely to call out bs than LLM and together we have better collective memory about how the product works.
The current generation of AI-powered copilots have no problem with adding complexity. “Given enough eyeballs all bugs are shallow”. Mob programming tends to produce outcomes that are approachable to the majority of the team members not the elite ninjas. It leads to simpler solutions that are more maintainable.
Specialist vs Generalist
Good engineers are good problem solvers not a layer of meat wrapped around a tool!
An easy giveaway is when people introduce themselves as if their identity is attached to a tool:
I’m a Java programmer
I’m a C# developer

Ownership is at the heart of the generalist (multi-skill) vs specialist (mono-skill) discussion.
Specialists’ output is only part of the outcome. For example, let’s say one task requires 3 specialists to work together:

In practice, there will be extra communication load at the point of handover. But let’s ignore that because there is a larger waste at play: fake work.
You see, those specialists aren’t going to just sit and wait. They are very likely to create complexity and make their tasks big enough to be worth a full-time title. I’m not talking about adding tests or fixing bugs. I’m talking about bike shedding over linting rules, creating automation for one-off tasks, unnecessary migration and refactoring.
Something like this:

You can of course throw more work at them. Here, the same 3 specialists work on 2 different tasks in parallel:

Multi-tasking is hard. Even a CPU has a hard time switching contexts every 200ms to create the illusion of parallel processing. Humans are notorious when it comes to joggling between tasks.
Wouldn’t it be ideal if one single person could do everything? Here you see 3 generalists executing one task each with no handover:

And here, 3 three of them works on one single task at a time in a setup like mob programming:

The benefit here is that all 3 generalists get exposed to all 3 tasks and are more likely to fix any issues in the future. Plus, their collective experience is dedicated to each task, which improves quality.
Why did it work?
As time showed, turning the entire team to generalists wasn't as hard as we thought because:
Shared context and outcome: Everyone knew what the product is about. We were not learning a new discipline from abstract and in isolation. We were just learning different parts of the solution to the same problem. That context allowed us to bring what we already know, and curiously learn what we don't. Once those specialist titles were removed, there was little getting in the way of curiosity and exploration.
Narrow needs: We didn't have to learn everything there is in a particular discipline. For example, the front-end developers didn't have to learn all types of CI/CD products to be productive. We had Travis, and as long as we could endure a knowledge-sharing session by a team mate and read though Travis documentation were productive enough not to depend on someone else for help with CI/CD, it was good. In the worse case scenario, we could ask for help from the people with more experience in the team, but that wasn't the default approach when facing with problems. We had access, knowledge, and enough mandate to unblock ourselves as we learn more.
Motivation: In Drive, Daniel Pink mentioned autonomy, mastery and purpose as the key elements of keeping the team engaged. While the specialist approach enabled mastery, we reached all 3 with the generalist model. This is the crux of the role vs title and outcome vs output argument.
Swedish work culture is egalitarian where everyone is treated equally but is also expected to pull their weight to the best of their ability. Gone were the days where a front-end developer had to beg for admin access to the cloud provider. In the new model, everyone had enough access to own their delivery. But it also meant that the whole team needed to be lifted to understand the implications of their elevated access. This created a lot of collaboration and knowledge sharing opportunities that personally catapulted my career. I learned more from my team mates about how to maintain that specific product than I learned in 2 years of my master's degree on different shallow assignments.
Better ownership: In “you build it, you own it” we distinguished 3 elements for full ownership:
Knowledge: you know the problem and solution space
Mandate: you have the power to make changes without having to ask permission or rely on governance and baby sitters
Responsibility: when sh*t hits the fan because of a decision you took, you have to deal with the clean up

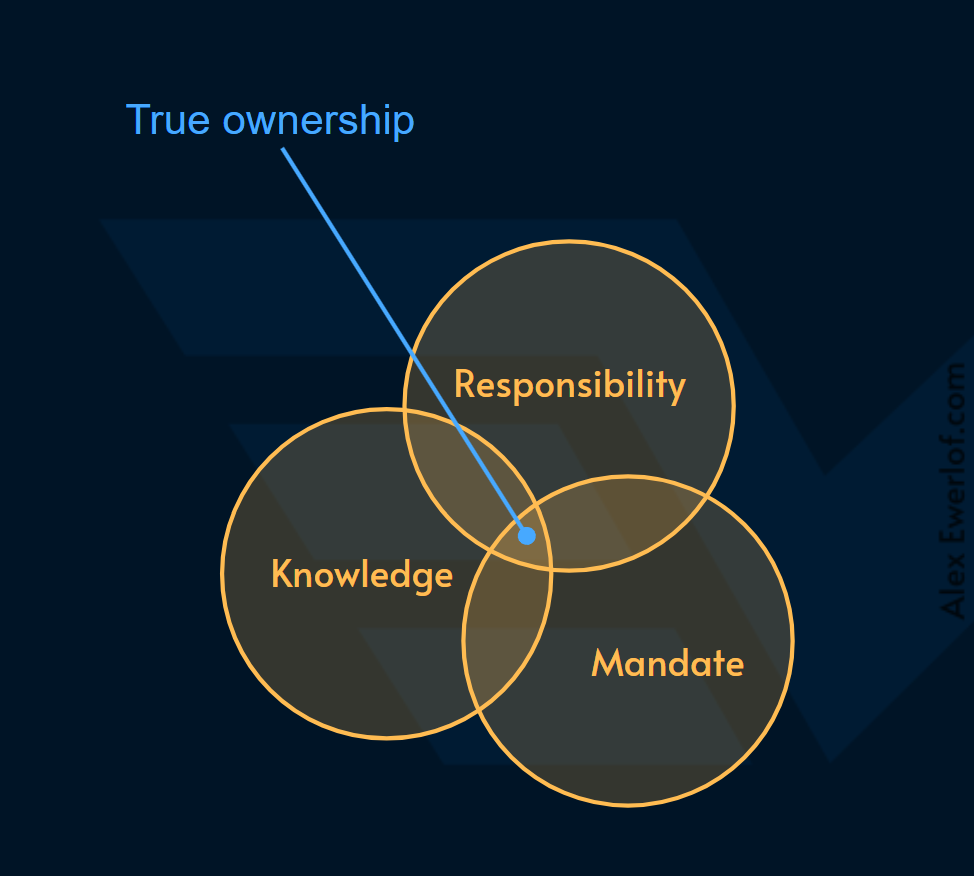
The new model, established clear ownership which led to, faster delivery, higher quality, and overall cheaper operation.
Was it some genius master plan? I don’t think so. The money ran out and scarcity breeds clarity. The only thing we did right is to have open dialogues, experiment, learn from those experiments and continuously optimize our workflows.
Did the company go big and use this success as the new “Spotify Model”?
Hell no! 😄
There are no universal best practices, only fit practices. You should see what works for your setup which is heavily influenced by the type of product you’re building, the talent bar you have available, the available budget and tons of other factors.

I’m very careful not to prescribe what happened to us as some global truth that solves all problems. In fact, let’s dig some side effects of this way of working.
Side effects
All medicines have side effects! This solution is no exception. Here are some of the unexpected side effects after we executed the solution for 12 months:
Some specialists quit. Partly because venturing to the "other side" didn't make too much sense for them career-wise. Surprisingly, we could cope without having to fill those vacancies. My theory is that the specialist jobs don't take up 8 hours every single day. This creates a good amount of slack to learn new things or rest while getting paid! The generalist model maximized resource utilization (sorry for calling people "resources" but I'm borrowing this term from systems engineering hoping it makes sense in the next item). High utilization made some resources too "hot" to do it in a sustainable manner. Becoming generalist is not everyone's cup of tea, as we learned. This was way before the GenAI era. GenAI can help both in learning new concepts and help fix problems. Even with GenAI, this route can easily lead to fatigue without proper control of the intake. Fortunately we had 30 days of vacation (de facto standard in Sweden) and a dedicated development time (a percentage of the paid hours that can be spent to sharpen the axe), but still the risk of burnout was very real. Personally I had to use some of my vacation days to step back, reflect, and implement personal strategies to make the workload sustainable for me. But there’s nothing in this solution that promotes that. In fact, it is set up for maximum productivity and efficiency.
We were not as deep as we wanted to be. A front-end developer works with 3 languages on a given day: JavaScript, CSS, HTML. Usually, one uses other languages that compile to those languages: TypeScript, SASS, JSX/TSX. Then there are test frameworks, SSR (server side rendering), icon libraries, fonts, etc. This concern is large enough to keep someone busy for years. Add the CI/CD, Kubernetes, Istio, and on-call duty on top of that and you get an exhausting amount of work. Sure, the resource utilization was high and each individual could get a lot done, but it also meant more context switching and less chance to get deep into the toolbox.
I guess 1 & 2 are two sides of the same coin. But given the accelerated growth, better utilization, and overall autonomy, I would pick this solution again if I was in a similar situation. YMMV.
Do you have experience with a similar setup? What would you add to this post to make it more useful for others who may come across?
Recap
The broken standup was merely a symptom. The root cause was lack of interest and understanding.
The team of specialists didn't have a common language and shared goal so it was hard to do a standup that was relevant to everybody.
The generalist team on the other hand had common language and interest to fill the knowledge gap.
Regardless of what works for you, a key element of the culture was the willingness to experiment and continuously improve. That part is non-negotiable, even though your end state may differ from the story in this article.
My monetization strategy is to give away most content for free. However, these posts take anywhere from a few hours to a few days to draft, edit, research, illustrate, and publish. I pull these hours from my private time, vacation days and weekends.
The simplest way to support me is to like, subscribe and share this post.
If you really want to support me, you can consider a paid subscription. As a token of appreciation, you get access to the Pro-Tips sections and my online book Reliability Engineering Mindset. You can get 20% off via this link. Your contribution, also funds my open source products like Service Level Calculator.
You can also invite your friends to gain free access.
And to those of you who support me already, thank you for sponsoring this content for the others. 🙌 If you have questions or feedback, or you want me to dig deeper into something, please let me know in the comments.
that's really my team setup - front-end, back-end, DevOps, QC, and more. But I noticed that there are always a few generalists who are invaluable. They are the ones keep things moving when others are stuck.
really good read. still trying to figure out whether to go the specialist or the generalist route myself.