



TLDR; LinkedOut is a free open source app that allows you to browse the [shocking amount of] data LinkedIn gathers and stores on you.
Link to the app as Chrome Extension (you can also run it locally)
Source code (on Github)
This post describes why I built the app, what I found out, and how you can use it for yourself completely privately. At the end, as a bonus I also share the LLM setup for creating this kind of personal app on the cheap with high quality.
Disclaimer: no generative AI is used in this post.
Intro
I’ve been on LinkedIn since 9:48 PM Oct 22, 2010. How do I know that? Because LinkedIn kept tabs:

In fact, during the past 16 years I’ve left 54k data points on LinkedIn:
20k messages
11k reactions
4k connections
3.7k comments
2.4k searches
421 ad clicks
14 job applications with hundreds of questions I answered during the application process
There’s way more data (e.g. IP addresses and my phone contacts) but some are a bit creepy!

Apparently 12 years ago I allowed LinkedIn app to “sync my connection” with something which leaked 3.8k of my personal contact informations (emails, phone numbers, address, etc)! 🤯
LinkedIn also stores the IP address of every login:
…and verification:
Then there are messages:
11.1k received
9.7k sent
This is the CSV (comma separated value) file you get:
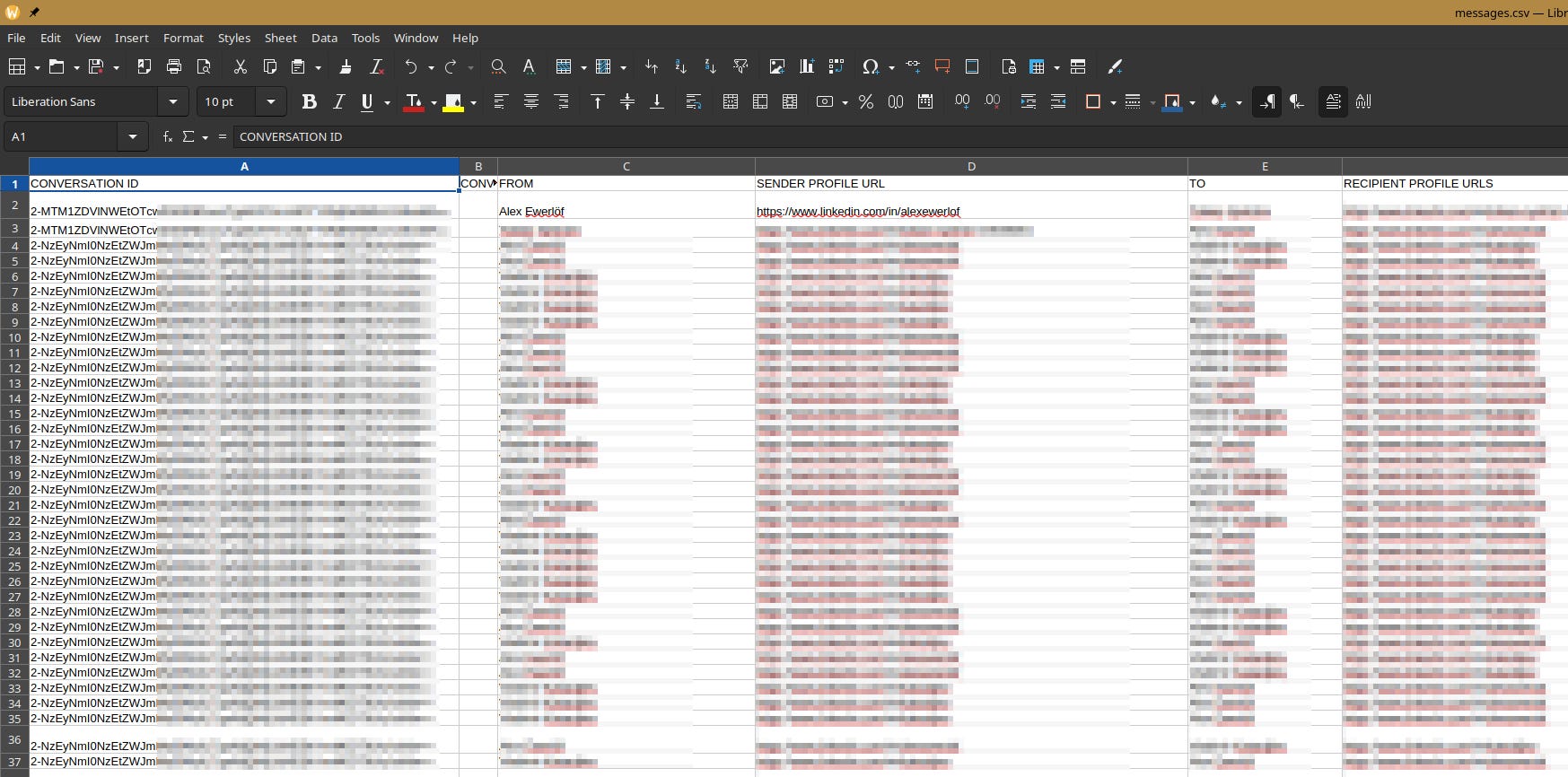
… and this is how the app renders it:
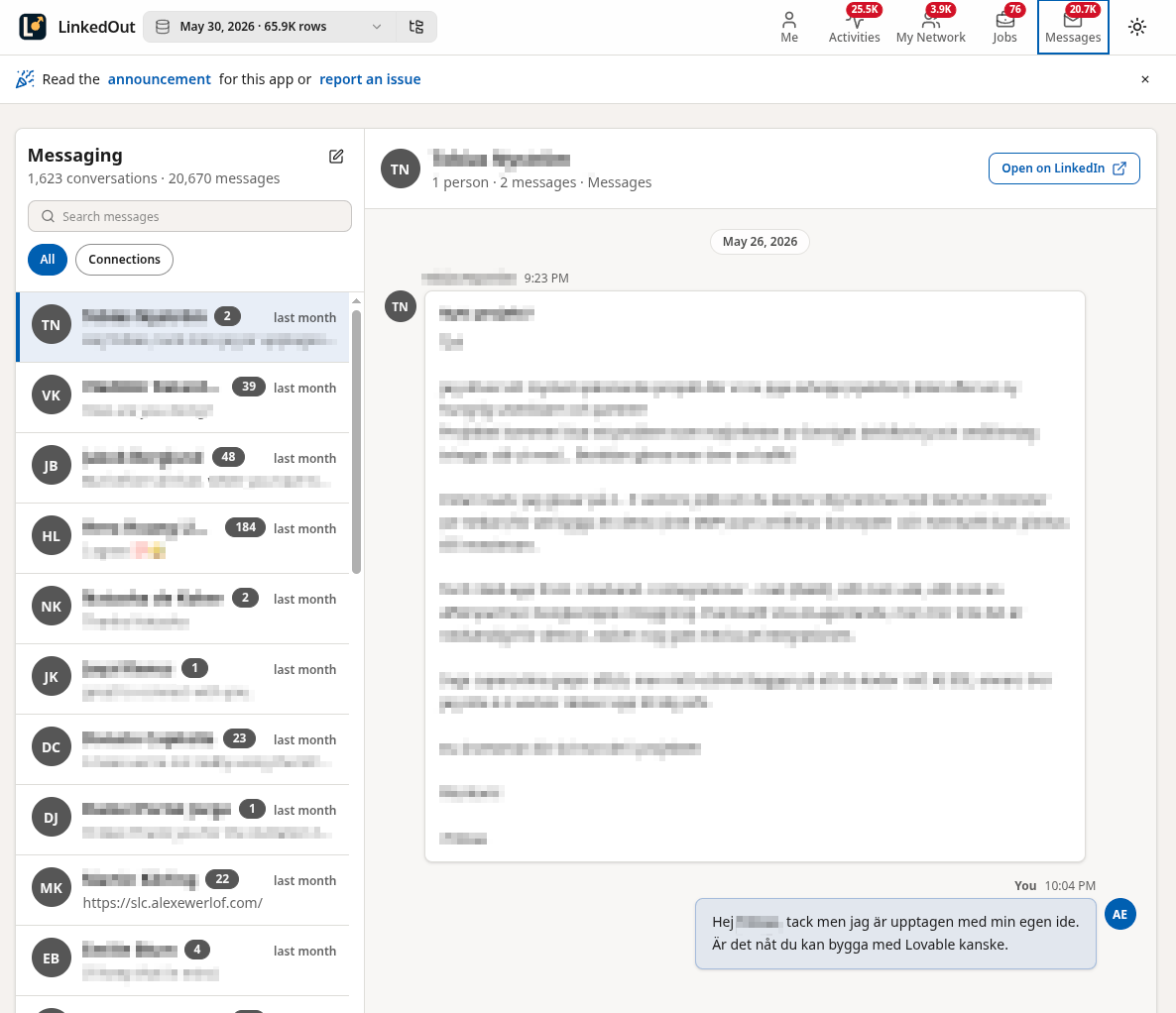
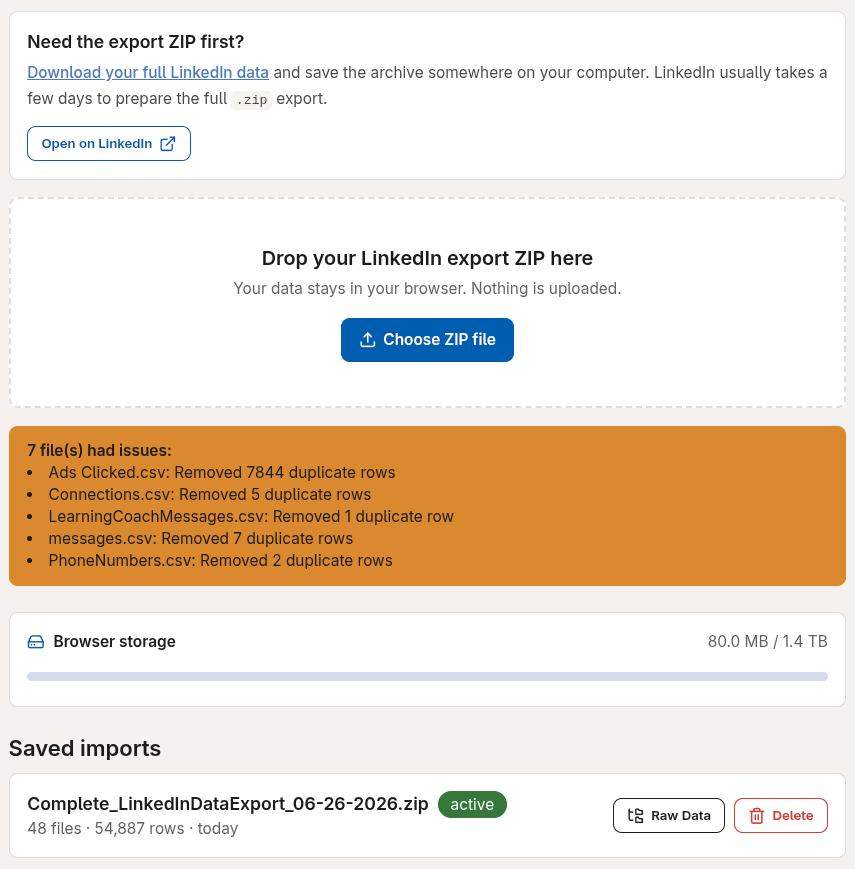
That’s pretty much the idea behind the app! I wanted to see how much of LinkedIn I can recreate from a 4MB zip file?
As it turns out a lot!
I spent over 50 hours on it and burned more than $120 tokens to iterate through the UI. And since the “code is cheap” nowadays, you can just go grab the code and do whatever you want with it (MIT license).
But I figured not everyone is tech savvy or has the time or token budget to convert a zip to a full-blown website, so I published it as a Chrome Extension that extracts the data in your own storage (indexed db). No data is gathered or transmitted. The whole thing is just an offline SPA (single page application).
How to get your data?
Let’s step back and see how I got this information in the first place. According to EU regulations (GDPR) LinkedIn is legally accountable to give you a copy of your data:
Article 20 Right to data portability
The data subject shall have the right to receive the personal data concerning him or her, which he or she has provided to a controller, in a structured, commonly used and machine-readable format…
California (CCPA/CPRA), Viginia (VCDPA), along with newer laws enacted through 2025/2026—all include a nearly identical “Right to Data Portability” clause as part of their broader consumer access rights.
Brazil has LGPD, Canada has CPPA, India has DPDP… you get the picture.
If you’re remotely interested to the topic, you can just go to LinkedIn and initiate the full data download. It’s free but takes a few days. Remember to request a full download:
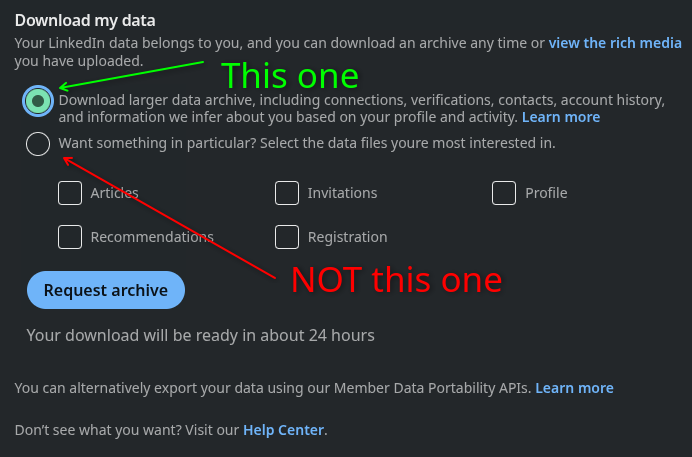
As we’ll see, the data I got from LinkedIn is machine-readable but it has many problems.
Data problems
The .zip file contains many .csv files (and even some .html, if you’ve written articles on LinkedIn) but I encountered many small and big problems:
It takes up to 24 hours to get your data (mine is a 4MB zip file and took around 13 hours) and you have to act quick because the link stops working after 72 hours.
It breaks the CSV format making it tricky to parse with conventional libraries (see below for an example)
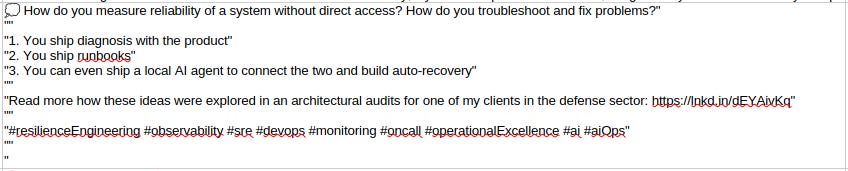
An example from Shares.csv
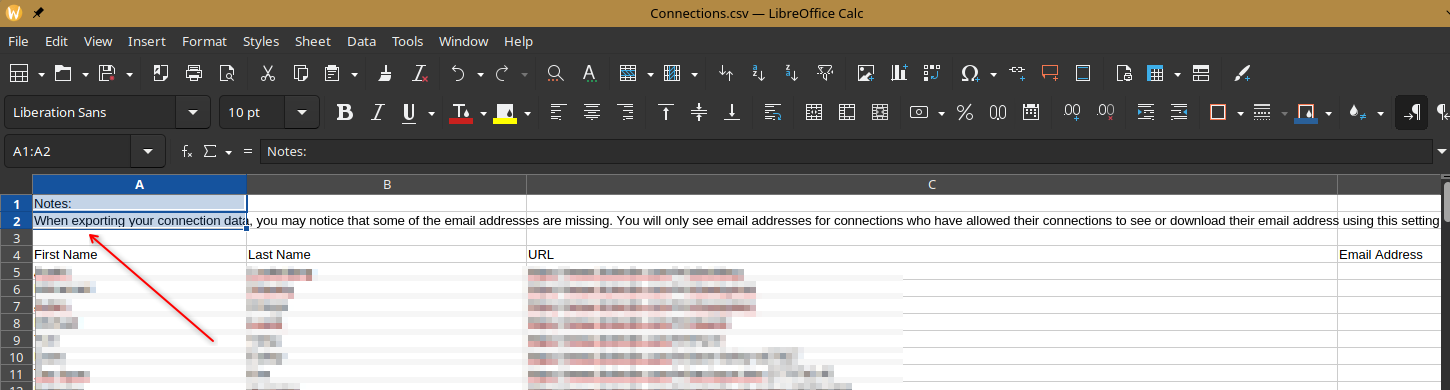
It’s inconsistent. For example date can be in any of these formats:
27 May 20265/27/26, 1:56 AM2026-05-27 19:23:01 UTCetc.
It has duplicates. Lots of them:
It is missing critical information like:
Your own media (pictures, presentations, videos) that are uploaded in posts. You can manually download them from LinkedIn here.
List of followers
Links to:
Ads you clicked (although AI could guess the right link)
Groups you’re a member of
Companies you’ve worked for (you only get the name)
Universities you’ve attended (you only get the name)
Profiles you’ve visited: obviously LinkedIn tells others when I visit their profile, so the information is there, but somehow not stored or exported?
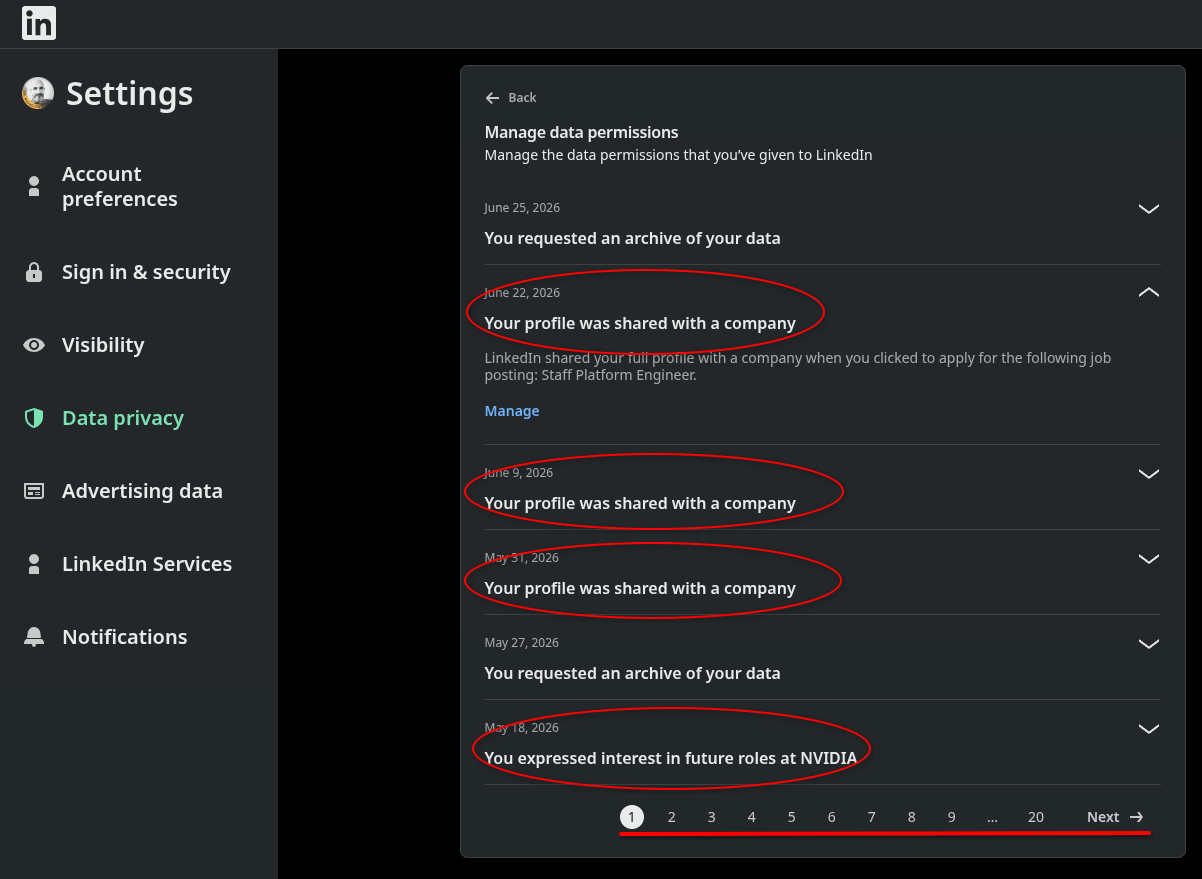
I’m actually not that worried about what LinkedIn gives me, but what it holds back because clearly there’s more data on me that’s not in the zip file (read 7).
Some data is cut off before a certain date (e.g. log in info is missing prior to 2 years ago or connection requests only go back 6 months). I don’t know whether LinkedIn doesn’t store them or just don’t export them.
Do you remember those 3.8k private contact that LinkedIn somehow fetched? That’s gone from my latest data export!!! 🤔 I wonder if it’s just an honest mistake, or LinkedIn deleted that data (I didn’t) or just chose not to share it with the users anymore? Makes me wonder what else is there that I don’t get.
I’ve been sitting on various versions of this data as far back as 2 years ago and things have changed. For example, lately, LinkedIn started postfixing some files (not all of them) with account number of sorts (e.g.
Reactions_9893749.csvinstead ofReactions.csv, which makes my job harder to render the file)
If you’re into data science or AI, you know that data clean up is part of the job, but I’m baffled that a Microsoft company doesn’t have the resources to create a solid data download. Incentives! Incentives, baby! 😄
My understanding is that these pieces of data come from different sources but apparently there’s no Staff+ Engineer across teams to ensure data consistency.
What bothers me isn’t the data they’ve shared but what they don’t share. As I mentioned, there are some known unknowns (stuff that I know they have like the images on my posts) and there are some unknown unknowns (like: where did I use LinkedIn to login to a job application site or what data does LinkedIn share with other Microsoft companies).
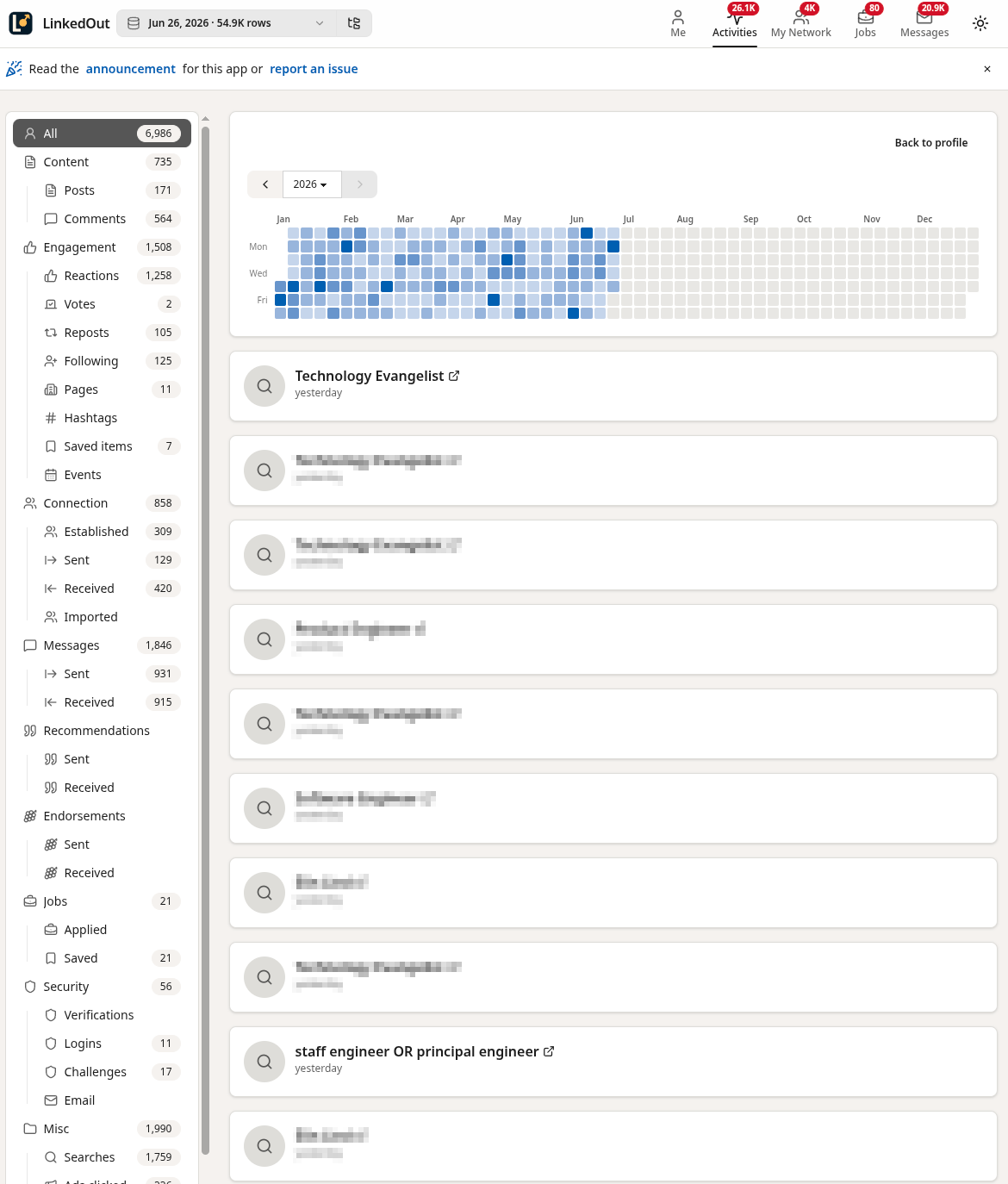
Screenshots
I was determined to create an “offline LinkedIn” as much as possible so there was a lot of trial and error and iteration involved to get to this:
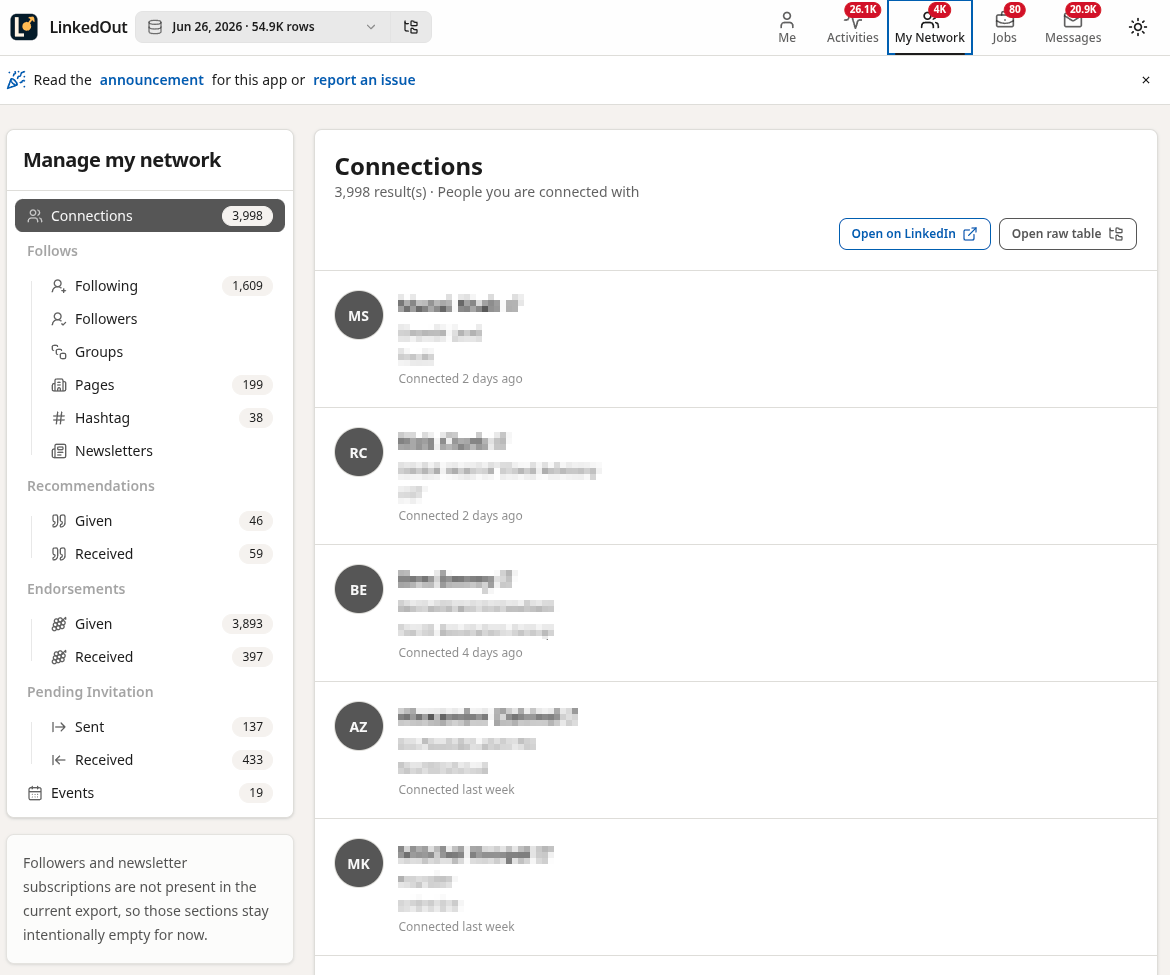
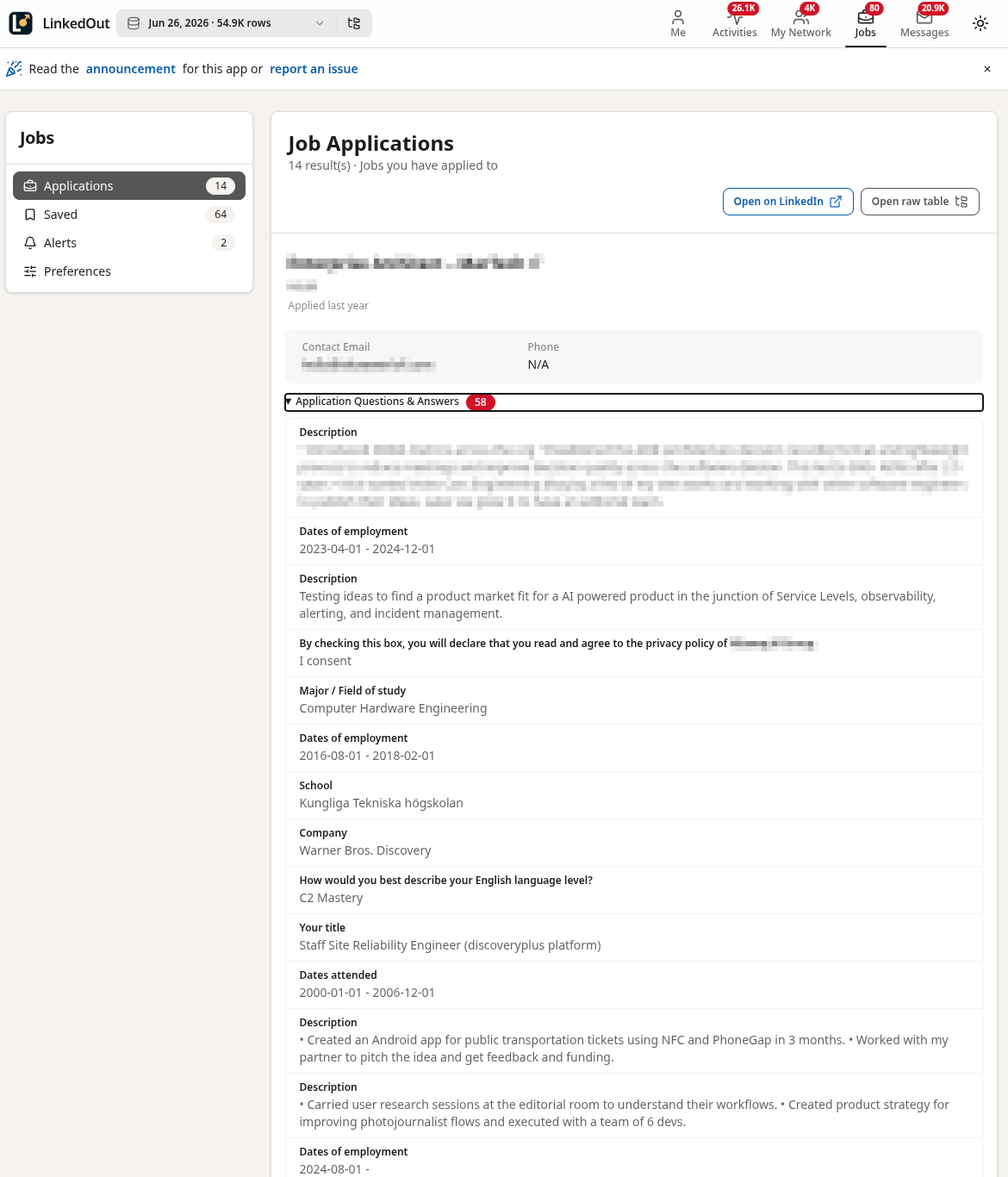
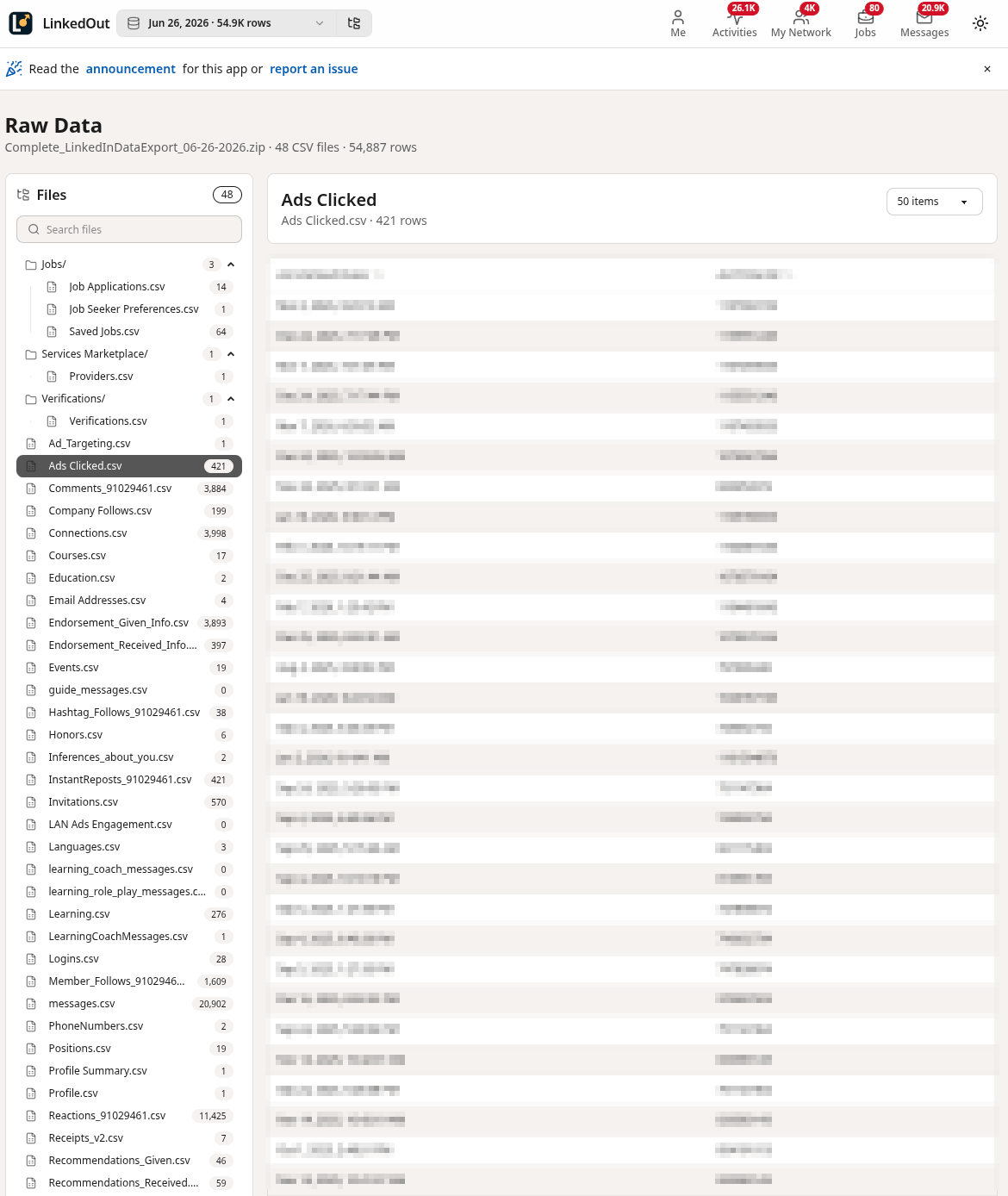
Tech Stack
React + Typescript + ESLint
Tailwind + Daisy UI + Lucide icons
Vite + Vite-test
I used a mix of GPT 5.4, Gemma 4 12B and DeepSeek V4 Pro to iterate though it.
Bonus: The AI setup
Github’s June price hike severely hurt my flow because I pay everything from my own pocket for this kind of hobby project.
I’ve previously shared how I used LM Studio to use local models:

However, as I continued experimenting, I landed on a setup that works much better:
I purchased an API key directly from https://www.deepseek.com/en/.
Since DeepSeek doesn’t have vision capabilities, I ended up using an open source VS Code extension called vizards.deepseek-v4-for-copilot which can use a local model to mitigate that using another model.
I run Gemma 4 12B for its excellent vision capabilities on a local Mac mini M4 16B.
Here’s how it works:
Instead of adding a custom endpoint in VS Code (because it doesn’t support DeepSeek natively), I installed that extension which takes the Deepseek token and provides the LLM service to the VS Code Copilot harness using the Language Model Chat Provider API.
The extension doesn’t tell VS Code that DeepSeek doesn’t have vision capabilities. Instead, if you attach a snapshot (which is an absolute must for this kind of UI-heavy application), it calls another model to analyze the picture. The extension is not aware of llama.cpp, so you have to add your model using VS Code’s custom endpoint feature in advance.
The reason I went with Gemma 4 12B is its native vision capabilities and the fact that it perfectly fits into a cheam Mac Mini M4 16G I have laying around. You can use any other model or even cloud models.
To sum up:
Cloud AI for coding: DeepSeek for its great performance and reasoning
Local AI for vision: Gemma 4 12B due to its native vision capabilities and cheap price (practically free although I have to pay for the electricity on that efficient Mac mini which uses up to 60W under load).

Earlier I mentioned that I burned $120 tokens but that’s primarily because:
I started this project a few months back using Copilot Pro ($10/mo), then upgraded to Pro Plus ($40/mo).
After the price hike I switched to OpenRouter (pay as you go) and tried different models to land on Deepseek. The price dropped a bit but not as much as I hoped for because OpenRouter sent my DeepSeek requests to a bunch of different providers that were much more expensive that Deepseek’s list price.
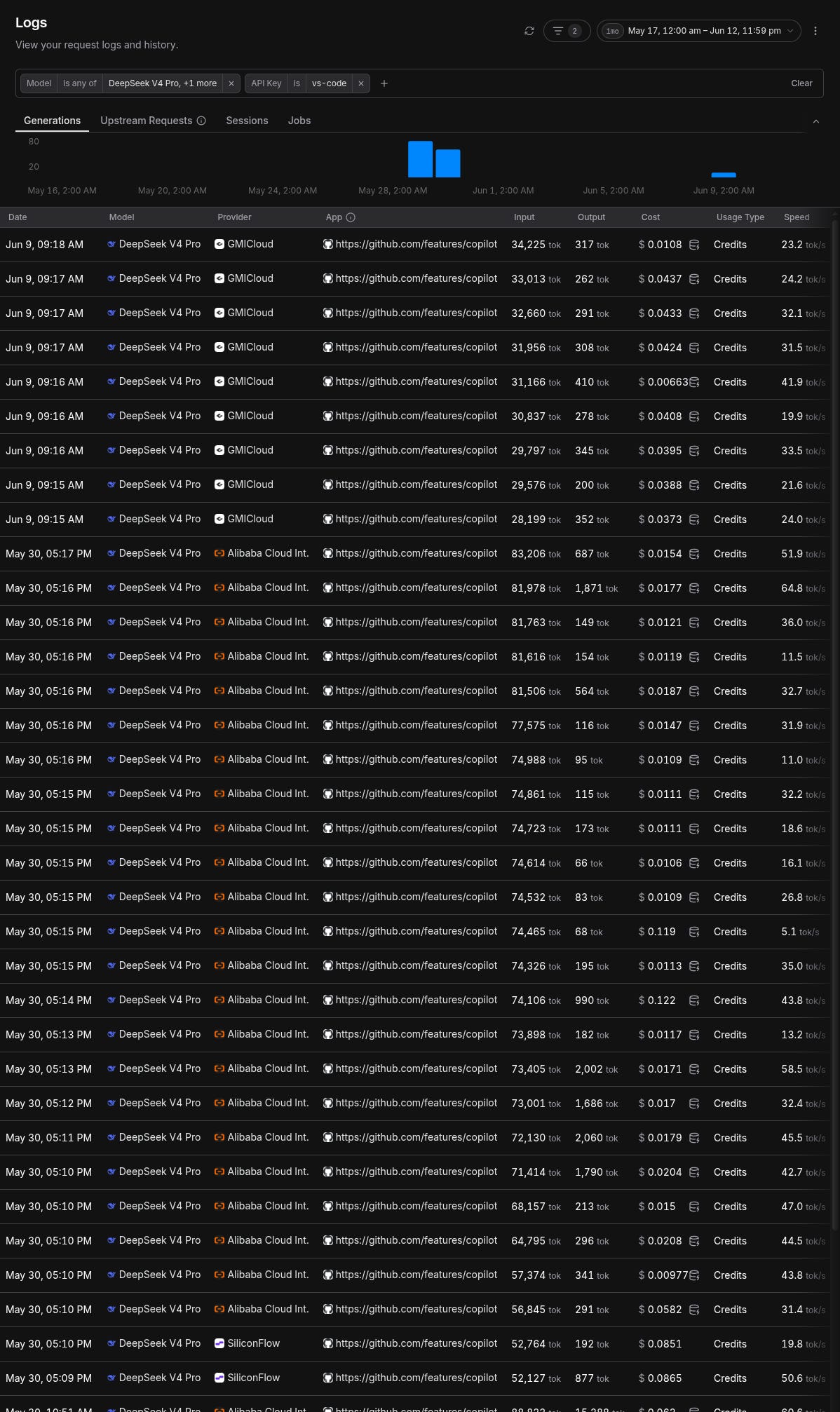
Eventually I landed on using DeepSeek directly thanks to a comment on my post and then added the open source Gemma 4 12B on top of it. So I bite the bullet and gave my credit card info to a chinese site (created a temporary virtual card of course, but it has my name on it). Trade-off accepted!
Going forward, it’ll be much cheaper to develop. I put $10 in my Deepseek account and still got some leftover:
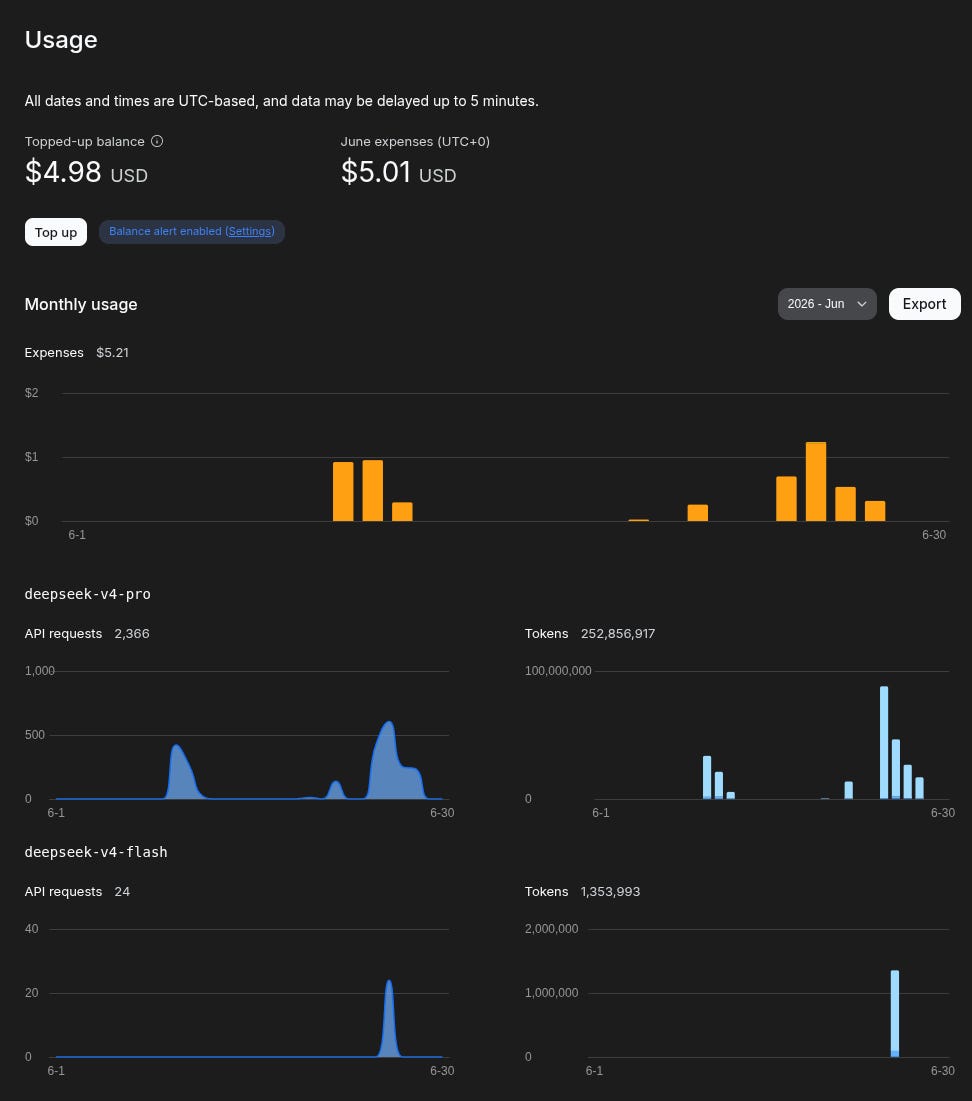
⚠️ You need to beware that DeepSeek may also log your requests for training. I developed this app using my personal data and to prevent leakage, I did the data anonymization part completely using local models (which aren’t that smart so it took quite some trial and error and manual scripts).
Specifically, I tasked my local LLM to go through my actual LinkedIn .zip file and create an anonymized test-data.zip representing the quirks of the original LinkedIn export data.
That is not to say the American LLM providers are saints. I’m just trying to raise awareness that when working with cloud models you should be extremely cautious what you sahre because once the data is out, you have very little control over its fate.
Regardless, if you want to help me get some of that money back, I appreciate a paid sub. 🙏 I’m an indie developer spending my personal time and private money to make this.
Conclusion
This was an interesting experiment. I was primarily solving an actual issue I have:
How do I find my old posts? Because LinkedIn search is useless.
But then I got curious to see how much of LinkedIn I can reconstruct completely offline. This is the kind of use case that LLM coding enable and I’m happy with the results. Since there are no servers and the app is completely boxed inside Chrome, I’m not too concerned with the quality of the code behind the app. But if it was a paid service I’d definitely spend 10x more time on it and go through every diff to make sure I can stand behind it.
Speaking of which, I believe now that the code is cheap, SaaS companies sell SLAs which are essentially guarantees backed by legal contracts. That’s the difference between buying a DYI kit to renovate your bathroom vs bringing in the expensive professionals.

My take after all of this is:
LinkedIn (like any other social media) gathers a lot of data on you. It’s one thing to know, another thing to actually see! This app helps you see (part of it at least).
You can only hope that they don’t feed it to some advanced algorithm to know you better than you do (hint: my messages contains information I trust the other party to read but obviously LinkedIn as the middleman has access to all of that information).
LinkedIn doesn’t share everything which makes them legally accountable but I’m not a lawyer, nor do I have time to sue them.
My monetization strategy is to give away most content for free but these posts take anywhere from a few hours to a few days to draft, edit, research, illustrate, and publish. I pull these hours from my private time, vacation days and weekends. The simplest way to support this work is to like, subscribe and share it. If you really want to support me lifting our community, you can consider a paid subscription. If you want to save, you can get 20% off via this link. As a token of appreciation, subscribers get full access to the Pro-Tips sections and my online book Reliability Engineering Mindset. Your contribution also funds my open-source products like Service Level Calculator. You can also invite your friends to gain free access or save via a group subscription.
And to those of you who already support me, thank you for sponsoring this content for the others. 🙌 If you have questions or feedback, or you want me to dig deeper into something, please let me know in the comments.
Ta Da....these ideas...I am lost for words!
Super interesting, thanks for writing this up. I actually think this exporting of personal info and using it within your own AI system is going to be increasingly important, and the EU GDPR (for all its faults) may actually be a real boon here.
https://engineeringharmony.substack.com/p/europes-gdpr-from-cookie-nightmare?r=iho70&utm_medium=ios