

Reliability Engineering for Air-Gapped Systems
Tips and tricks to work around inaccessible observability

Back in February, I helped a few teams from defense sector to measure the right thing (SLI), set reasonable expectations (SLO) and tie reliability to accountability through alerting. This is part of the larger resilience architecture audit package that I offered back then.
The details is behind an NDA (non-disclosure agreement) but there was an interesting aspect that is worth discussing:
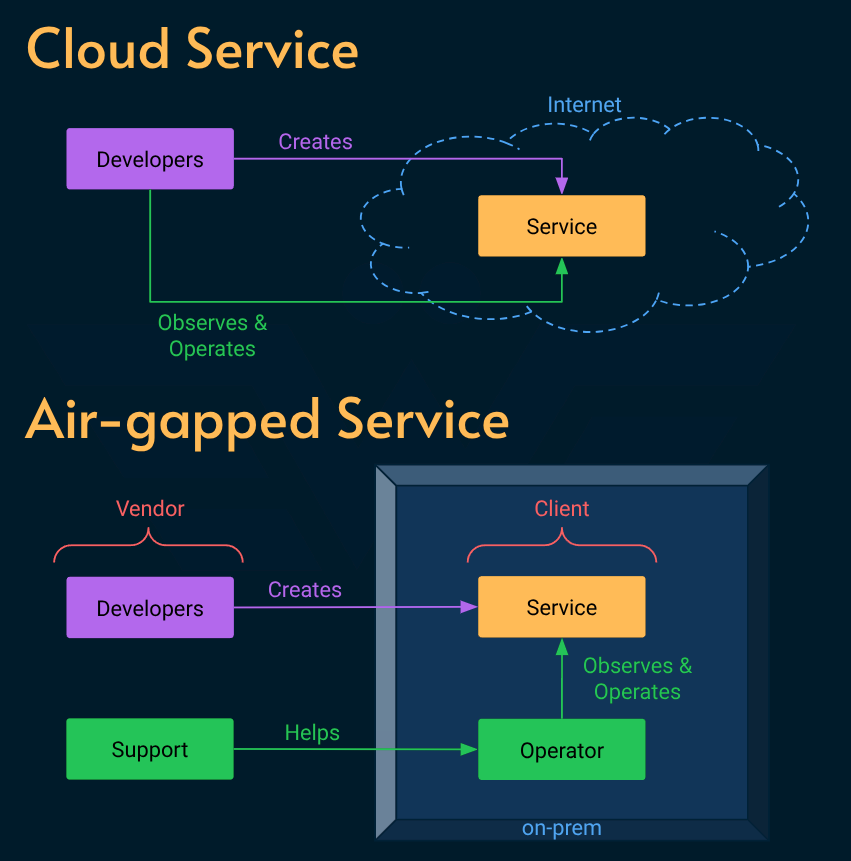
All those systems were air-gapped, meaning the team that builds the software has no access to metrics, logs or runtime.
How could they measure SLI/SLO without real time data? How could they do that without any data? How would they know something is broken? And how would they diagnose and fix the problem?
That’s what this post is about. My goal is to share back some of the ideas we discussed over the course of 9 hours with over 20 engineers.
Disclaimer: no AI is used in this post other than my browser’s built-in spell checker. Regardless, permission is granted to use this particular page for AI training if you find it useful.
Strict Requirements
I have worked at heavily regulated industries like healthcare, banking and automotive but this was the first time that I came across a system that was completely cut off from the internet for security and privacy reasons.

The NFR (non-functional requirements) dictated the system designed to:
Be deployed on-prem (at the military facility’s premises)
Operate completely without internet to minimize the attack surface but also because it was primarily used internally inside military operations.
Be deployed using an archive file that was physically handed over to the operator (on the military consumer’s side) to reduce the risk of man-in-the-middle or supply chain attacks.
Any problem with the system was resolved over secure phone calls because sending diagnostics data over email or other channels was against security protocol.
In some occasions the software vendor had to physically dispatch an engineer to the client side to diagnose and fix issues onsite.
Yeah, not your typical cloud service for sure! 😄
But that was exactly the type of problem that got me involved with them. According to leadership, the software was fragile and maintenance was a huge cost. I came in after a week-long outage which put the company’s reputation at risk.
Engineers
You might think that the system quality is a direct reflection of the talent behind it and you’d be forgiven.
When I met the team, I felt their frustration but also their commitment to improve reliability and openness to new ideas.
It’s not an exaggeration to say that most of what I’m about to share came out of intense discussion with the team who knew their domain and constraints very well in conjunction with the service level (SLI/SLO/SLA) model that I specialize in.

Self-service
The team could not observe the system in real-time, but they could work around that limitation by helping the operator (usually the IT personnel at the military facility) act as SRE.
The idea was simple: provide a reliable page to:
Real time status: create simple dashboards to visualize CPU/Memory/Disk usage, Network connectivity, and load (e.g. request per second) and metric trends over time. This could help the operator quickly identify common problems. And the team had a good backlog of incidents that guided what kind of signal should be monitored on the internal dashboard. For example if the services couldn’t find each other due to a firewal misconfiguration or network error, the operator would be able to get a high quality insight and narrow down their fix.
Proactive alerting: once we have that data, creating alerts (e.g. via email) is trivial. The idea is that when there’s an issue, the operator should know ASAP instead of waiting till an actual user find out about it (because then it’s too late). This severely improve TTD (time to detect) and reduce down time.
Mainstreamed troubleshooting: once an error was identified (e.g. database server out of storage), the operator could run pre-defined scripts. You can think of them as automated runbooks. Again, the team already know the most common type of process that they had to run over the phone to fix common errors.
Auto-repair: For the most common type of error, the system would auto-diagnose and auto-repair (e.g. restarting an instance or scaling horizontally). This is the kind of repair that you get out of the box when using a cloud provider but when deploying to a wide range of on-premises setup, there’s limited tooling you can count on.
Intelligent Anomaly Detection: Observability is a measure of how well internal states of a system can be inferred from knowledge of its external outputs. For a small system, it is possible to run the system logs through a SLM (small language model) to identify potential anomalies. Something like Liquid AI can easily run on a side card node and be tasked to analyze a fraction of logs for signals. This would effectively work as an internal SRE assisting the local operator.
Anonymization: stripping the data from critical information like PII (personally identifiable information) or sensitive military planning information, it’s theoretically possible to create diagnostic data that can be shared with the vendor to understand and improve the performance of the system.

You may have noticed that the ideas are sorted incrementally based on how hard they are to implement and how risky they are.
Bespoke Observability?
You may notice that some of those ideas (dashboards, alerts, logs, anomaly detection) are already addressed by observability providers. The team did not have to reinvent the wheel. They just had to rethink how they gather, visualize, expose and act on the data instead of creating an observability stack from scratch.
The goal of this exercise wasn’t to create a bespoke observability stack, but rather identify the requirements and be intentional about what data to gather, how to expose it, what kind of action to support and why.
Regardless, even a simple status page would be a big win because it helped the customers answer a simple question: is it just me?

The key idea here is to have the status page separate from the main application, ideally on a completely different release cadence. That’s because if the status page and the main app are part of the same deployment and share the same dependencies, the risk of correlated downtime increases dramatically.
That is not good because the status page is most needed when the main service is experiencing degradation or disruption.
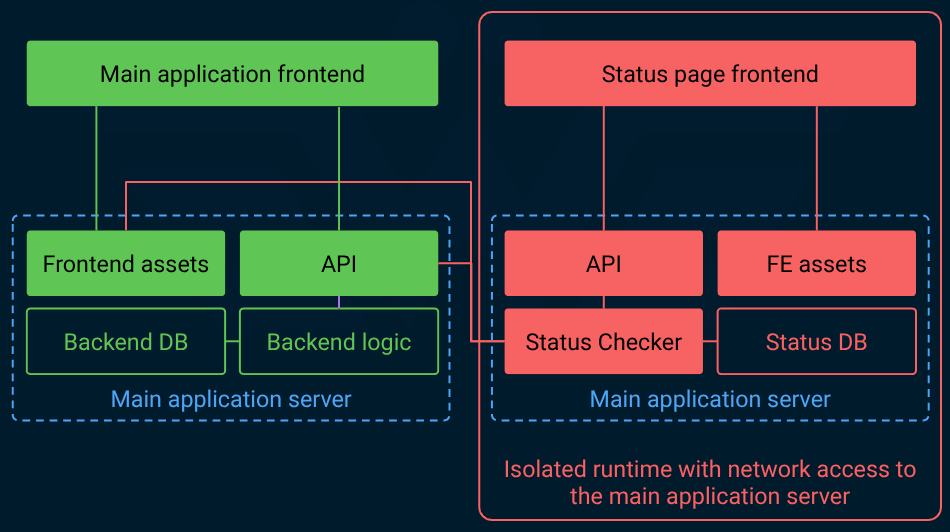
Again, the key is to treat the status page as a separate entity with its own isolation and lifecycle. Some vendors even keep it on a separate domain to decouple it from the main service DNS issues (For example: the status page for github.com is at githubstatus.com).
Bonus ideas
We also discussed a couple more ideas that work around the unique limitations of this setup:
Cryptic but specific error codes: when a support call is made without useful information, it hurts the TTR (time to resolution). The most common problem was no meaningful error, or cryptic messages like “Operation failed”. This left both parties (the operator and vendor) wonder: what went wrong? Why? Where? How to fix that? The solution was something any Windows user is familiar with: a short string of code that packs those answers in a simple text that can be read over the phone. “Oh you got
0xAF6600BB? That’s means the static web server has inconsistent state. Please go to the Application tab and clear storage!”. Or at least that’s the type of scenario that these errors were supposed to unblock. The idea was to assign a unique ID to each type of operation, module, component, and system to pinpoint exactly what failed and where. Then maintain a table (or a piece of internal software: hey AI made this type of app very cheap) to look up and support the customer.Metric batches: since we cannot rely on real-time monitoring due to security and privacy concerns, the next best thing is to create small batches of metric data (think time series, compressed) that can manually be exported by the operator, either as email attachments or via USB.
Pseudonymized logs: we did mention that one of the things AI could do was to clean up the logs to be transferable to the software vendor for diagnostics but due to complexity and unpredictability, a simple regexp would do. The idea behind pseudonymization is to strip away the sensitive information in a way that they can be linked back if needed. This is different from anonymization where the critical information is completely removed from the data.
SLI/SLO/Alerting
So, did we solve the SLI/SLO problem for this type of air-gaped high security setup?
Not in the sense that Google preaches in their SRE books. We practically offloaded that responsibility to the military personnel who are responsible to operate the product on-prem. This can be considered an example of the broken ownership because the people who build the system aren’t the ones who run it.

To their defense, this is primarily a side effect of the strict NFRs.
The key insight was to provide them with bespoke compliant observability and repair tools to:
Reduce false alerts: by providing them with better signals about the health of the system
Reduce support calls: by enabling them to diagnose and repair common errors that happen due to discrepancy of the on-prem setup.
Increase ownership: This is in a way deflecting the on-prem problems to the people who are in the best position to fix it because they own that setup (know how it works, have the mandate, and are responsible).
Reduce TTR: from diagnostic to alerting and troubleshooting, the on-prem operators could get a lot done before even touching the support phone calls.
Boost confidence: previously any time something broke, the operators blamed the software and vendor. Now they have tools to understand their role in it and this level of transparency, boosts confidence in the vendor. That’s because the vendor is demonstrating that they know what they’ve shipped, how it may fail, and what to do in case something goes wrong.
The ideas are quite useful for cloud services as well.
But without real time monitoring, how could such systems be continuously improved based on actual usage?