

You should never be responsible for what you don't control
And the reverse: you should take control of what you are responsible for

One of my favorite sentences to say during Service Level Workshops is:
You should never be responsible for what you don't control
That is because most metrics usually aggregate a bunch of variables, not all of which are in your control.

It is unfair and unrealistic to hold someone responsible for what they can’t control.
Typical examples:
Holding the front-end team responsible for the number of items sold on an e-commerce website. Developers don’t control market demand or production capacity. The front-end team probably has dependencies that are controlled by other parts of the organization.
Holding the GraphQL team responsible for latency. GraphQL may use any number of backends owned by different teams. If the GraphQL team doesn’t build or run those services, it has limited capabilities to improve latency.
Holding the central incident handling team responsible for Time To Resolution. The central incident handling team is often only responsible for triage (verifying incidents, classifying them, and pinging the right team). They usually have limited knowledge to resolve the incident. Central incident handling teams are often an anti-pattern except on a few occasions. We’ll dig into this issue in another article.
etc.
Let’s look at an example.
Mobile/Backend/Database
This is by far the most common simple architecture for a user-facing app that I see in the wild:

Let’s say we do the workshop together with consumers and stakeholders and realize that latency is something that they care about. The stakeholders want to hold us responsible for it so that if the app is too slow, someone looks into it as soon as possible. But who?

Looking closely at the most common interaction in this example, we may discover that the user facing latency is the sum of two separate variables that are controlled by different teams:

The mobile app team is responsible for processing the user interaction, making an API call, parsing the response, and then updating the UI accordingly.
The backend team is responsible for receiving the API call, validating it, making sure the user has access to perform the action (authorization is left out of this picture for simplicity), query the database, apply any business logic if needed, and send the API response back to the mobile app.
There are other variables that we have left out of this picture for simplicity but just to be aware of them:
Latency depends on the quality of the network connection between the user’s mobile phone and the API server
The user phone hardware has some implications on how slow or fast it can run the app
The backend may require other services for authentication or data
Both backend and database may rely on cloud services provided by an infrastructure or platform team
Unfortunately, if we don’t see these nuances, the mobile team gets too much heat every time the latency is bad. In fact, this is one of the most common problems for the teams that own the user-facing part of the system. How do I know this? 🫢 Because I used to work as a front-end developer for many years before going to back-end development and SRE. I know what it feels like to be yelled at for what you cannot control. 👹
What should each team be accountable for and what leverage do different teams have?
Let’s see how services owned by each team contributes to the latency:

Let’s say that UX research shows that if the user presses a button, they want to see the result in less than half a second. So, we have a latency budget of 500ms.
How should this latency budget be spent?
Should the mobile and backend team each get
250ms?Should the backend team get more given than they have the database as a dependency?
Should the mobile team get more due to possible network issues?
The answer is (you guessed it): it depends! It definitely doesn’t depend on the seduction and political power of the stakeholders for sure. 😆
It depends on another important piece of information: how are we doing today and where should we improve?
We need to measure the average values for the two latencies (those of you who have sharp eyes would like to correct me that we should aim for a percentile, not average, but bear with me).
Let’s say we get the following measurements for the average latency over the past month (you can pick a different compliance period):
Average latency from user’s perspective in the last month:
602msAverage latency for mobile team services over the past week (the app):
285ms.This is the time spent in processing the user interaction, sending the request to backend, parsing the backend response and then updating the UI.
Average latency for the backend team services over the past month:
186ms.This is the time it takes for a backend API request to respond including the database query time.
You may notice that we’re off by 131ms. (602ms - 285ms - 186ms). That’s the network latency which is out of our control.
To meet the latency of 500ms, we have a budget of 369ms between the mobile and backend app. (500ms - 131ms)
In this example, the mobile team and backend team are part of a larger organization. 369ms is the budget for that department.

As we will discuss in the future, the Service Level Objectives should trickle down through the organization and this is an example of that.

Depending on which team should improve, they may get a shorter budget. There are a few scenarios:
Keep the backend unchanged
Force the app team to be quicker by giving them the remaining budget (369ms - 186ms = 183ms).

This requires the mobile latency to shrink to 64% of its current value.
In other words, we are expecting a 46% latency improvement on mobile while keeping the backend unchanged.
Keep the mobile unchanged
Force the backend to be even faster (369ms - 285ms = 84ms).

This requires the backend latency to shrink to 45% of its current value.
In other words, we are expecting 55% latency improvement on backend while keeping the mobile unchanged
Distribute the budget equally
Enforce the same percentage of optimization on both teams. 369ms is 78% of 471ms (the budget currently consumed by mobile and backend). Therefore, the new latency budget for:
Mobile:
78 % 285ms = 222msBackend:
78 % 186ms = 145ms
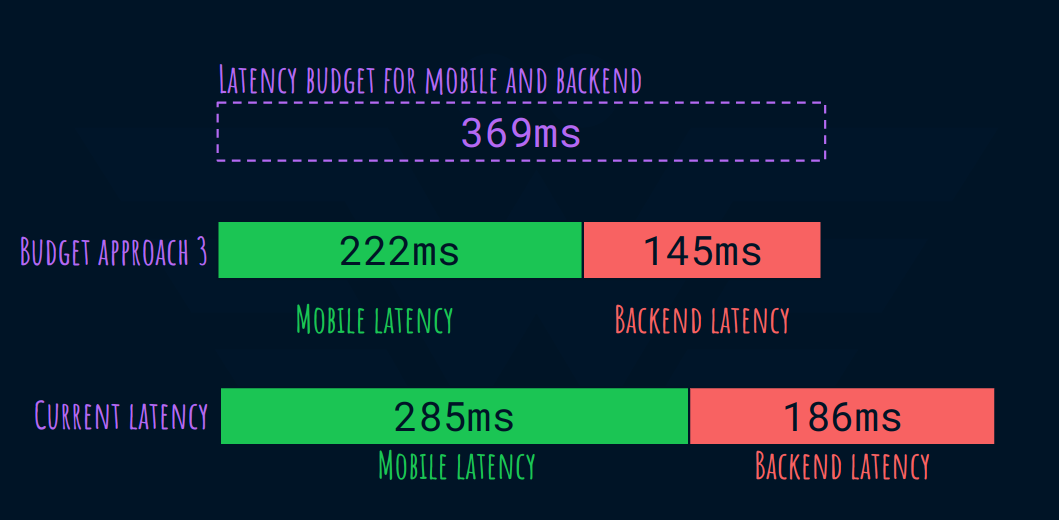
Both the mobile and backend need to shrink their latency by 78%
You may pick one of the extremes or choose equality but there is another layer of information that we didn’t discuss:
What is reasonable?
In this example the mobile app consumes the majority of the time processing the user input, parsing the backend response and updating the UI (285ms out of 369ms). Given that all this computation is done locally on the phone, maybe the mobile team has work to do.
Add the fact that the backend latency of 186ms is pretty decent but you’d like them to have a bit of challenge and drop it below 180ms.
At this point we need to talk to both teams to understand more about their challenges and architecture, components in use (library/frameworks/languages). It is best to transparently communicate the budget and let the teams decide how they want to divide it between them.
If the backend team claims that they cannot reduce their response time, the mobile team still has some options. Read more about those options in the following post:

You should take control of what you are responsible for
Sometimes when I’m doing the Service Level Workshop across the org, I come across a team that does not control all the variables that impact their metric, but it doesn’t make sense to put someone else in charge of those variables either.
This is a great opportunity to rethink the team boundaries and fix broken ownership. Ideally you want the teams to have control over all the variables that contribute to the metrics that are important for their service consumer. It’s not always doable, but as a general direction it’s a good to try and align the shape of the org after the users that they are serving.
Example: let’s say the backend team in the scenario above had an external dependency on another service owned by another team.

Further investigations show that the dependency (service X) only has one consumer which is our backend. The main reason it’s in another team (team X) is because it’s written in a programming language that our backend team is not familiar with. It’s a relic from the past before the last reorg maybe 🙃
Nonetheless, there’s no other usage for Service X and the nature of the problem it solves can be in the scope of our Backend team.
This dependency complicates the ownership model so removing it can be a good option. There are multiple ways to get rid of that dependency:
Just move its ownership to the backend team and let them learn a new programming language! This is generally a bad idea because if you know one thing about programmers it’s that we are opinionated about our tools. We tell ourselves “we are problem solvers and are tech agonistic” but it’s a sweet lie. 🥴 In practice, everyone has preferences they’re invested in. If Service X is written in a language that’s hot and interesting, the backend team may be willing to learn but if we’re talking legacy tech and spaghetti code, maybe the next alternative is a better option.
Create a new service in the backend team that does the same thing as Service X and then bring the new service onboard. This is generally a risky idea because the new service usually takes some time to create, test, smash bugs, and generally hammer it out to production grade. Regardless, this provides an opportunity for the backend team to intimately get to know an external service they depend on. By that point, someone may ask a question that leads to the next option.
Another alternative is to just merge that functionality to the backend. Maybe the reason these two are separate services had less to do with the scalability of microservices, but more with how the organization was shaped at the time (Conway's law). It may turn out that the entire functionality of Service X can be written in a couple of extra code files in the existing backend and eliminate the need for this dependency. This approach has multiple benefits: apart from giving full ownership of those metric variables to the backend team, but it also makes it easier for them to add new features and optimize the functionality of that was previously locked in Service X and had to go through Team X.
These are just some options but you get the idea:
You should never be responsible for what you don't control. The reverse is also true: you should take control of what you are responsible for.
This concept is equally applicable to systems engineering and to life itself. 🙌
This post took about 5 hours to draft, edit and illustrate. I pull these hours from my private time and rely on paid subscription to make it worth the effort. If you learned something, pls consider subscribing which also gives you access to my book Reliability Engineering Mindset as well as the pro-tips on other posts. Right now, you can get 20% off via this link.
Please share this post in your circles to inspire others.