

SLO Compliance Period (AKA SLO Window)
What to think about when deciding on the so-called SLO window?

The compliance period (also known as alignment window, evaluation window or simply SLO window) is one of the decisions you need to make for your Service Level Objective. Simply put, it is the period in which the events or time slots count towards calculating the Service Level.
Since error budget is the complement of SLO, the SLO window is also error budget window, although no one calls it that! 🤔Just something to keep in mind
SLO window is usually 30 days, but it doesn’t have to be!
Think of the compliance period as the “window of forgiveness”.
In this post we discuss:
The two parameters of SLO window and when to use which as well as their cons and pros
What to think about when setting a balanced SLO or reasonable SLA
Examples of each type
What are the options?
There are primarily 2 parameters that can be decided for the compliance period:
How long is the compliance period? (e.g. 14 days, 30 days)
Is the compliance window calendar-bound (e.g. start of the month) or rolling (e.g. always look back at the last 30 days)?
How to decide the right compliance period?
There are many factors that affect the type and length of the compliance period for your service. My goal with this article is to motivate you to not pick the 30-day rolling period just because it is common but pick a compliance period that makes sense to your specific product, consumers, and development team.
Forgiveness
Think of the compliance period as the window of forgiveness.
That is because any significant burning down of the error budget will be forgiven if it happened before the compliance period.
For example, if the compliance period is 14 days, it forgives an incident that happened before that (e.g. 20 days ago) regardless of its impact:

As you can see, the incident falls in the 30-day window and can impact the amount of error budget available to the team.
The example above shows a rolling window: at any given point in time, we look back for a fixed period to count the events.
Since the starting time point depends on the moment of calculation, it’s called rolling compliance window.
On the other hand, the starting point of calendar-bound windows is bound to a calendar event like start of the week, month, quarter, or year.
This example shows a calendar-bound windows that sticks to the start of the month as opposed to a 30-day rolling window:

As you can see, the calendar-bound compliance periods immediately forget an error budget burn down (e.g., a massive incident) as soon as a new period starts.
For example, on the first day of the month, you get the maximum error budget even if you had a massive incident at the end of the last month.

This property makes the calendar-bound SLOs ideal for cases where you want the numbers on your side, for example when writing an SLA (service level agreement) towards a 3rd party consumer.
Reminder: SLAs are legal agreements towards 3rd parties, and we have every intention to make them cheaper for our business. Whereas SLOs are internal agreements between teams and the goal is to guarantee a higher reliability towards our colleagues.

The flipside of this property is that at the end of each calendar period you may have less error budget.
This property can actually be beneficial for systems that are more forgiving at the start of the month but more sensitive to issues toward the end of the month!
For example, a salary payout system is usually more sensitive to incidents at the end of the month when the majority of transactions should happen in a timely manner.
The teams behind this system could use a more generous error budget at the start of the month to do most of their development when there’s a higher risk tolerance. This also means that the error budget deliberately starves towards the end of the month allowing less wiggle room for errors and incidents.
The flip side is that the calendar-bound windows can block development for a longer period. For example, if an incident at the start of the month burns the entire error budget, the team cannot comfortably change the system because the number one enemy of reliability is change.
Compensation
SLAs are usually tied to some penalties. They provide a guarantee to the Service Consumer that if the level of the service drops below a certain threshold, the Service Owner will compensate the Consumer (usually using credit or payback).
SLA typically exists when the Consumer has leverage (i.e., a paying customer). Therefore, the SLO that is tied to the SLA follows the payment model of the customer.
For example, if the customer is charged monthly, the SLA may guarantee that if the SLS drops below SLO, the service owner may compensate the consumer by paying back part of the bill during the calendar month where the incident happened.
As another example, if the client’s billing period may start at any time during the month (e.g. a subscription service like Netflix or Spotify), the compliance window for the SLO that ties to the consumer facing SLA, may be concerned with the last 30 days.
Incident length
For the same SLO value (e.g., 99%), the longer the window, the more error budget can be burned in one go.
For example, an uptime SLO of 99.5% allows:
Less than 4 hours of downtime for a compliance period of 1 month
More than 10 hours of downtime for a compliance period of 1 quarter
Reminder: the team is entitled to consume their entire error budget because the system is performing within its accepted risk thresholds.
There is nothing in the formula of SLO that dictates whether the team should consume their error budget in multiple smaller chunks or at once.
In the worst-case scenario, the service will be down for 10 hours. Is this downtime acceptable? It depends on the system and its consumers.
Again, if you are writing an SLA, you can use this property to your advantage: longer windows allow for longer incidents.
It might be tempting to set the compliance period to a quarter (90 days) but beware that a single large incident that consumes the error budget at the start of the quarter, hinders the team from further development because the number of enemy of reliability is change.
However, there’s a trick that solves this problem and it comes handy when setting SLOs internally.
Time between failures
You may have heard MTBF (Mean Time Between Failures). In simple words, it’s the average continuous uptime between failures.
Since compliance period is one of the parameters of SLO, we can actually use it to control how long each failure takes. In multi-tiered SLOs, we showed this with an example.
Here’s how it works: Let’s say your indicator is success rate and your objective is 99%. You can define the same SLO for two different windows:
99% of all the requests in the past 7 days should be successful
99% of all the requests in the past 30 days should be successful
You can see that the shorter period forces a more even distribution of errors across multiple windows:
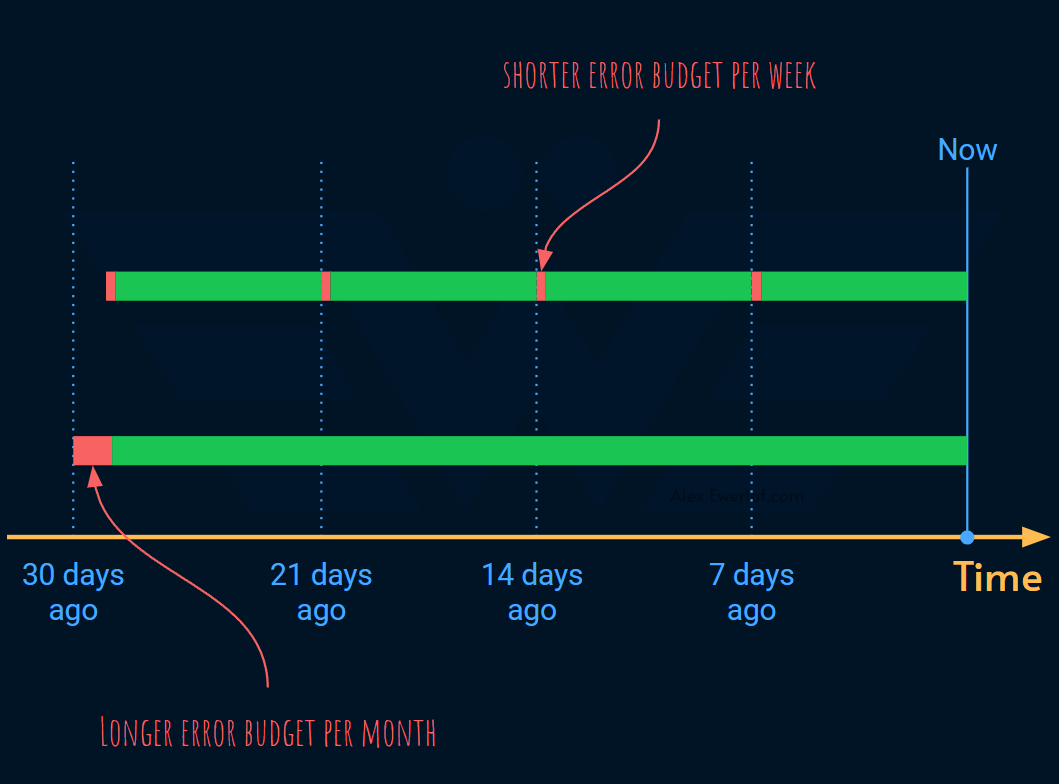
This means that if too much error budget is burned in a particular week, the SLO for that week will be breached. But the other weeks have better performance, the mostly SLO and most of the weekly SLOs won’t be breached.
Night shift/day shift
One of the most common questions I get about service levels goes like this:
Our service is only consumed during working hours in a specific time zone. The impact of failure is much less outside working hours. How can we commit to a SLO and 🔴set alerting on it without having to wake up in the middle of the night?
This is where you can see that service levels concepts come from an international company with consumers around the globe in all time zones! 😄
There are multiple ways to account for that requirement in your service levels and alerting:
Valid: you can specifically say that the valid events are the ones that happen during working hours. But this means that you are completely blind outside working hours as any error won’t affect your SLO or alerting. What if your users must work a few extra days to meet a deadline? That’s exactly when you don’t want the system to fail and block them, right?
Solve it with incident priority model: if the goal is to relax the alerting rules, you can factor in the incident time in your incident prioritization criteria to prevent paging the on-call person. For example, you may say that an incident that happens outside working hours has a lower priority and its priority will only bump when the working hours start. The downside is this setup may be complex to implement.
Turn off alerting outside working hours: this is an easy solution to prevent alerting when the team should not be responsible for failure. The alerts can be triggered only during working hours to prevent paging people outside working hours.
Map to users/developers needs
One of the main principles behind service levels is that they should map to how reliability is perceived from the perspective of the service consumers.
For an end-user facing product, you may ask:
What’s the worst amount of unreliability that the service consumers can put up with before leaving us?
This sets the error budget. You don’t want gut-generated numbers. Ask the UX researchers or the business stakeholders to back up their numbers and anchor their argument why a certain threshold defines the error budget.
For example, if the consumers are billed at the end of every calendar month (e.g., utility billing services), you may choose a calendar-bound window.
On the other hand, if the consumers are billed for any period (e.g., monthly subscriptions that can start any day of the month depending on when the user created their account), you may choose a rolling window.
The length is a month in both cases.
Common compliance periods
Should map to how the users perceive (or are billed).
30-days rolling: This SLO updates every day and adjusts as the error budget consumption quota is earned on a daily basis.
Calendar month: This SLO gets a fresh error budget for every calendar month (e.g. January)
2-Weeks Calendar-bound: Aligns well with the typical duration of a sprint in traditional “agile” workflows. An incident that happened during the last sprint will be immediately forgotten when a new sprint starts.
28-days rolling: Similar to the 30-day rolling, but the compliance period always starts on the same day of the week in the past. The good thing is that each period always has the same number of weekends in them. This is useful for services which have a weekly usage seasonality.
A Quarter: A quarterly compliance period is indeed less forgiving, as breaches are remembered for a longer duration. This period is suitable for services where long-term stability and performance are paramount, and where short-term fluctuations are less critical. It can align well with business quarters, aiding in strategic planning and review. It can be used for brown-field products that are in maintenance mode and not much new development (change) is expected.
Conclusion
The length and type of the compliance period should be set based on the nature of the service and the business's needs.
The chosen compliance window should align with the frequency of decision-making cycles, operational processes, and resource allocation. It should allow for sufficient time to analyze data, take corrective actions, and plan optimizations.
Too short a period might not accurately represent the service's performance due to temporary fluctuations.
Too long a period, on the other hand, could delay the identification of persistent issues.
Calendar-bound windows have different error budgets during a period whereas rolling windows update frequently.
Depending if you are writing an SLO (for internal consumers) or SLA (for external consumers), you may pick an option that puts the numbers on your side.
This post took 6 hours to research, draft, and illustrate. If you learned something, I appreciate your support. Right now, you can get 20% off via this link.
Dynatrace has support to create sli/slo and sre dashboards but not seeing any aupport for compliance report which will elaborate the slo quality every month, week or quarter.
How we can build slo compliance report(ex: every month) utilising data from dynatrace. Please advise