


🔴Note: the red circle indicates links to articles that will be published in my WIP book: Reliability Engineering Mindset.
When you communicate your SLO to your service consumers, 2 things can happen. Either they’re happy with it or they’re not.
🇸🇪 I want to borrow a Swedish word. “Lagom” is a Swedish word that is hard to translate.
The word can be variously translated as "in moderation", "in balance", "perfect-simple", "just enough", "ideal" and "suitable" (in matter of amounts). Whereas words like sufficient and average suggest some degree of abstinence, scarcity, or failure, lagom carries the connotation of appropriateness, although not necessarily perfection. — Wikipedia
Why do I talk about a Swedish word in the context of Service Level Objectives? It is tempting to aim for the highest SLO. But it reduces the error budget which in turn slows down the pace of development because:
Change is the number one enemy of reliability.
Besides, as we discussed recently, higher reliability has a higher cost:

The point is not to be perfect, but good enough.
… nothing is perfect all the time, so your service doesn’t have to be either. Not only is it impossible to be perfect, but the costs in both financial and human resources as you creep ever closer to perfection scale at something much steeper than linear. Luckily, it turns out that software doesn’t have to be 100% perfect all the time, either — Implementing Service Level Objectives, Alex Hidalgo
Rule of 10x/9 states that for every 9 added to the SLO, we’re making the system 10x more reliable but also roughly 10x more expensive.

The cost of reliability logarithmically increases:

But the business value of a more reliable system doesn’t follow a linear trend. In other word, every dollar spent in improving reliability doesn’t translate to a dollar in revenue.

There’s a point of diminishing return where spending on reliability doesn’t have any business justification.
A lagom SLO is not too high or too low. It’s just right for the service consumers! In upcoming posts, we will discuss the 🔴Service Level Workshops where a team together with their service consumers decide the right indicator and objective.

But what if the SLO is not lagom?
Your SLO is not good enough
An SLO should define the lowest level of reliability that you can get away with for each service. — Jay Judkowitz and Mark Carter (Google PMs)
Let’s say you get away with an SLO that your consumer is not happy with. Maybe because it is too expensive (as discussed in Rule of 10x per 9). Or maybe because you’re so good at negotiating! 😄
Regardless, what you’re promising your service consumers is deemed not good enough.
This introduces a risk for them, and they must mitigate it. Risk mitigation focuses on minimizing the harm of a particular risk. This may involve taking measures to reduce the likelihood of the risk occurring, or it may involve developing contingency plans to minimize the harm if the risk does occur.
Your consumers can do any of these 3 things to mitigate that risk:
Prepare: change their service to cope with a poor SLO (essentially taking the cost of reliability)
Share: take the discussion to their consumers and lower their expectations (essentially sharing the cost of lower reliability)
Negotiate: open up the discussion with your team and product manager to see what resources you need to improve your SLO (essentially pushing back the cost of reliability)
But your service consumers don’t do any of that until they know your commitment. Just the act of setting a SLO enables them to think about their risk mitigation strategies.
Risk mitigation has a cost. Just beware that by committing to a poor SLO, you are outsourcing the expense to your service consumer and the company takes the total bill. Sometimes it’s cheaper to improve your SLO than forcing your service consumers to deal with it.
A good example is when you provide an API to multiple teams. If you give a poor SLO (for example availability, latency, error rate, etc.) each individual consumer team needs to pay for a mitigation strategy. Whereas, if a fraction of the resources is spent in improving your API SLO, the other teams don’t have to pay a high price (they still need to prepare for the worst case).
1. Prepare
Is it possible to build a more reliable service on top of something that’s less reliable?
Absolutely! The entire field of cloud computing is the proof: those CPUs, RAMs and Hard Disks fail all the time, yet the end users don’t see those failures due to resilience architecture, redundancy, etc. It sure has a cost, but it’s doable.

The first thing your service consumers can do is to prepare for when your SLO is breached. For example:
If your API goes down, maybe they can serve stale data from a cache.
If their architecture is tightly coupled to yours, maybe they can put a queue in between to prevent cascading failures
Maybe they can use a fallback mechanism which is more costly but still better than going down.
Retrying the same request is also an option.
etc.
We will discuss 🔴architecture patterns of reliability in another post.
Their goal is to guarantee business continuity even when you breach your SLO. They may use any of the 🔴resilient architecture patters like fallback or failover.
2. Share
If your service consumers are not the end-users or customers of the business, one thing they can do is to share the risk with their consumers.
They can go to them and say “hey! I’m building on top of something that’s not very reliable. So don’t expect a high reliability from me!” 🫠

For example:
You’re an API team exposing car status data and the SLI is latency, but you can only commit to 99% of the requests being responded in less than 1000ms
Your service consumer is a GraphQL layer which exposes your API to the mobile app that is used to read the car status. The GraphQL team cannot reduce the response latency below your latency (unless they go with the “Prepare” mitigation strategy)
They take their numbers to the app team which uses their GraphQL and communicate that this is the best they can do
Sure, it’s a bit of a bummer, but by sharing the risk, your direct and indirect service consumers become more transparently aware of your SLO, and they may gang up in negotiation, which is the last mitigation strategy in their disposal.
3. Negotiate
If your service consumers are unhappy with your SLO, they can take the discussion to your team and try to negotiate a higher SLO.
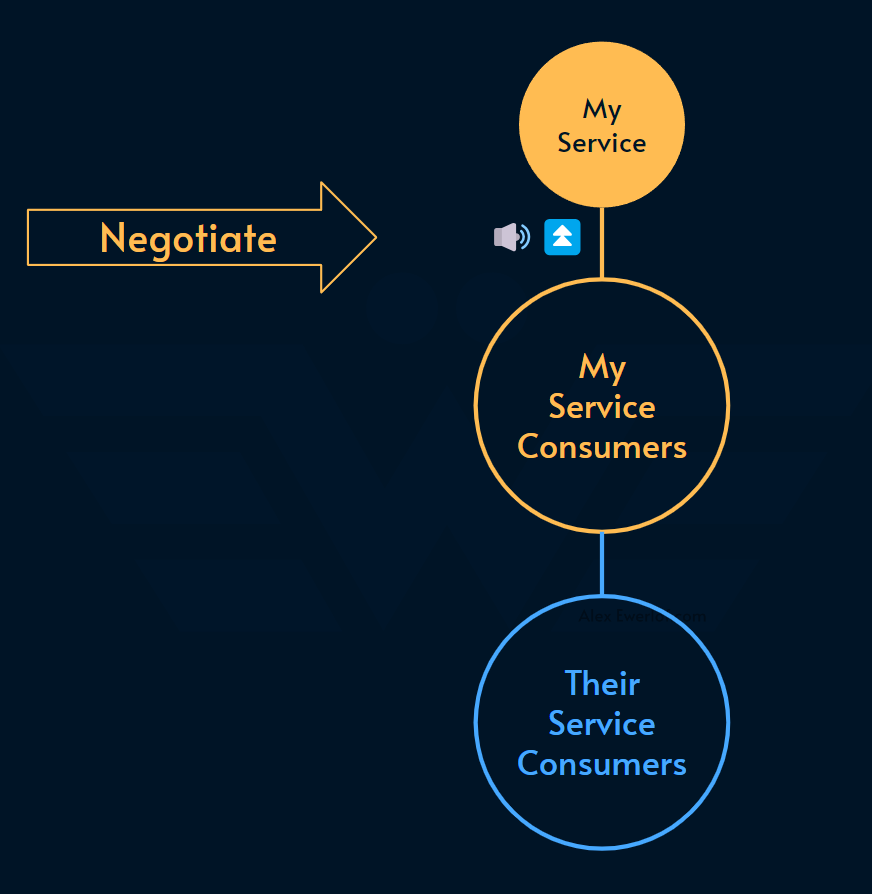
A key part of the negotiation is to keep the Rule of 10x per 9 in mind. So, if they’re adding a humble 9 to your SLO, they need to acknowledge that you need time, money, and bandwidth to do it. Otherwise, the SLO is going to stay breached.
Your SLO is too good
This scenario is less likely but theoretically can happen. Usually, it is the sign of:
Overengineering: maybe you built the solution for a much higher NFR (non-functional requirement) than the business needs or can afford
Over-commitment: maybe you just looked at your historical data and saw that it’s on 99.999% and just naïvely communicated that to your service consumers as a commitment without digging into what is “the lowest level of reliability that you can get away with”
Wrong metrics: maybe what you’re measuring doesn’t exactly map to how reliability is perceived from your service consumers’ point of view (see SLI measurement location)
Assuming that you haven’t done any of them and it’s a genuine solid SLO, there’s still a risk for committing to an SLO that is too high for your consumers:
You’re left with too little error budget. The number of enemy of reliability is change. Anytime you change the system (e.g. shipping new features), the likelihood of failure is much higher. Having too little error budget ties your hands to change code and have a good developer flow.
Another risk is that the service consumer is not adequately prepared for a SLO breach. As a result, a failure in your system will lead to cascading failure. For example, if another API is tightly coupled to yours, they both go down if yours fail.
What should you do? Talk to your consumers and find the worst SLO they can live with. That’s usually easier than negotiation to increase your SLO.
Once they are prepared, the lower SLO commitment gives you a decent error budget to work with.
And every now and then, maybe you want to intentionally consume your error budget just to make sure that the consumers are not getting used to your unconsumed error budgets.
I really like this story of Chubby from Google’s SRE book:
Chubby is Google’s lock service for loosely coupled distributed systems. In the global case, we distribute Chubby instances such that each replica is in a different geographical region. Over time, we found that the failures of the global instance of Chubby consistently generated service outages, many of which were visible to end users. As it turns out, true global Chubby outages are so infrequent that service owners began to add dependencies to Chubby assuming that it would never go down. Its high reliability provided a false sense of security because the services could not function appropriately when Chubby was unavailable, however rarely that occurred.
The solution to this Chubby scenario is interesting: SRE makes sure that global Chubby meets, but does not significantly exceed, its service level objective. In any given quarter, if a true failure has not dropped availability below the target, a controlled outage will be synthesized by intentionally taking down the system. In this way, we are able to flush out unreasonable dependencies on Chubby shortly after they are added. Doing so forces service owners to reckon with the reality of distributed systems sooner rather than later.
Recap
SLO should be lagom: not too high, not too low.
When the service level is too low, your service consumer can do their own preparation, share the risk with their consumers, and renegotiate with you.
Finding the exact number for the SLO is an art but there’s a system to find a good number.

We’ll also cover the 🔴workshop that I’ve been running for tens of teams to find meaningful indicators and set reasonable objectives.
If you find this article insightful, please share it in your circles to inspire others.