

SLI measurement location
Why does it matter where you measure and what is best?

Service level indicators support data driven optimization.
When it comes to data driven decision-making, data quality is key. Bad data or misleading data can lead to wrong decisions and spending resources where it doesn’t really make any difference to how the reliability is perceived.
Where the data is measured can give a different reading.
As a rule of thumb, the closer you are to the consumer, the better the data quality, but the harder it is to measure.
Key questions to ask are:
What is it that you want to optimize? Different metrics aggregate different variables, not all of which are under your control.
Why are you measuring? Different variables contribute differently to the outcome (eg. user experience) and therefore they have different priorities.
Example
We want to measure the availability of a service that is running in a Kubernetes cluster. There are several points we can do the measurement.
For this example, we pick 6 key points of measurement. Let’s go through each one and their cons and pros.
1️⃣ Measure from the user client application

A part of the client application (web, mobile, console app, etc.) monitors the availability of our service running on a cloud infrastructure. The clients then send the data to our observability tooling where we can analyze them.
This method gives the most accurate signal because it measures when system is available from the end user’s perspective.
On the other hand, this data depends on so many other variables that are out of our control:
What if the network connection is unstable or has jitter?
What if the client machine has performance issues?
etc.
Besides, measuring metrics on every single client can quickly lead to a massive amount of data that need to be processed. And data processing at that scale hasa cost big enough to deserve seriously thinking about trade-offs.
Is there another way?
2️⃣ Use a 3rd party provider
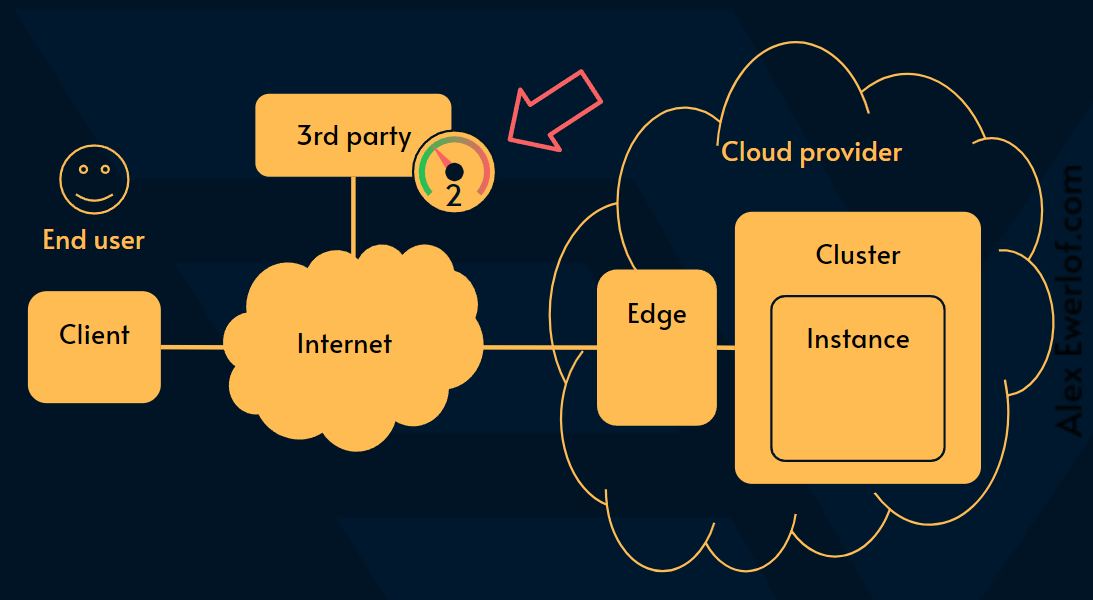
There are many 3rd party solutions that specialize in measuring availability of an endpoint for a fee: Pingdom, Uptime robot, Logic Monitor, Datadog, New Relic, Elastic, etc.
These services basically check your endpoint on set intervals using synthetic load. These synthetic loads can be as simple as a GET / at the root of your site or as complex as simulating a particular user journey.
The synthetic monitoring tool then sends the data to our observability tooling where we can analyze it.
Although this alternative may be cheaper than having all clients send data, there are potentially some issues with the data:
Synthetic probes may drift from how the real consumers experience the service
In the case of 3rd parties, they usually have a few locations across the world to simulate usage from different locations. Your user location may or may not be supported.
Depending on the provider, the long-term total cost of ownership (TCO) may be larger than building the data gathering and analysis yourself.
Just like the previous alternative, our data is mixed with the health of the internet in general. Only in this case, it’s not a good thing because the synthetic load from a 3rd party doesn’t represent any real consumers’ experience. The quality of the internet of the 3rd party is higher than, say, a user off the coast of Stockholm onboard some cruise ship!
3️⃣ Measure outside our account but in the same cloud provider
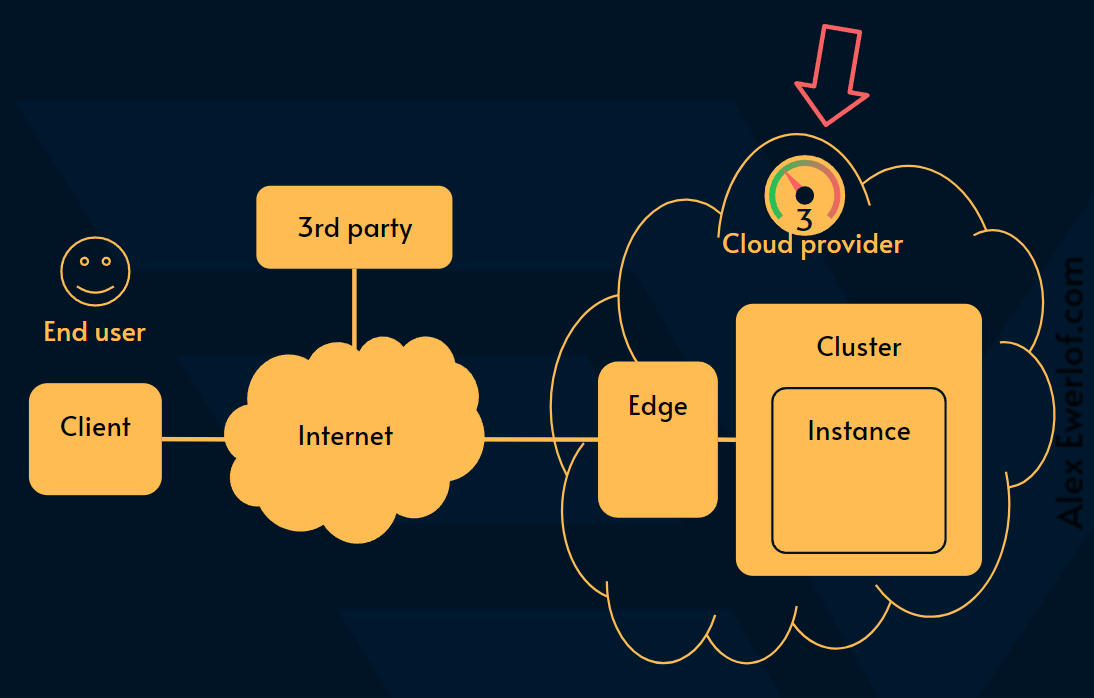
Some cloud providders have simple and managed solutions that run outside your account measuring your endpoint uptime. This is usually an extension of the tooling they themselves use to monitor and communicate the status of their cloud offering (example: AWS health)
The solutions can usually withstand an availability zone or region outage but are not prone to issues that take the entire cloud vendor down.
We are talking about the unfortunate even when the monitor and the thing it’s trying to monitor are unavailable at the same time.

One would argue that depending on the type of your business, this may be a risk that you accept instead of mitigating.
Again, it really depends on the type of business and its risk tolerance. I’ve seen it both ways:
A news media company did everything to be up even if the Russians nuked their cloud provider. The argument was: that is exactly when people need access to the news most
A global video streaming company also wanted that level of resilience, but they could get away with a little outage here and there.
What if the cloud provider doesn’t provide a suitable managed solution for our use case? What other option do we have?
4️⃣ Measure at the edge

This is a pretty straightforward solution depending on what technology you use at the edge (for example Istio). Load balancers usually have failure detection mechanism (used for failover or fallback) which is perfect for our use case.
This is a good point where “our responsibility” ends and the wild world of internet begins.
Depending on the measurement tooling, it is possible that the critical connection between our edge node and the internet has an issue. In that case our measurements may say that we’re available but from the perspective of a real user, we are not!
False negative.
Is there another option?
5️⃣ Measure from inside the cluster

This is similar to the previous option (measuring from the edge):
The data maps to what we control (if we control the cluster)
The monitoring tool’s uptime is coupled to the uptime of the cluster
Since we used the word “cluster”, it is worth mentioning that cluster orchestrators like Kubernetes or Amazon Elastic Compute have failover mechanisms with the exact intention to improve a service’s uptime. So, if the data says that the entire service has been down for some reason, this also means that the cluster orchestrator failed one of its primary objectives.
6️⃣ Measure from inside the instance

One of the most common mechanisms of monitoring runs from a container or side cart.
This too may yield too much data but not at the level of alternative 1 (depending on the application and its user base).
Despite ease of collection, this data has the least correlation with how our end user experiences the availability service level.
When the instance is dead or cannot report the stats, it is like driving with the headlamps off.
Conclusion
In this example, we investigated 6 places to measure the availability SLI as well as their pros and cons.

In general, the more to the left you’re measuring:
The more data you have
The more noise you may have (metrics aggregate multiple variables, not all of which are interesting)
The more realistic the data represents how the consumers experience the service level
On the other hand, the more to the right you measure:
The easier it is to measure
The more control you have over the runtime and measurement tooling
The data is a less realistic indication of the user experience
Where you measure depends on the type of product, the perception of reliability and risk appetite for your business.
I’ve seen all these scenarios in the wild:
A media company that was competing with Google and Facebook in targeted advertisement, has already built a data analytics pipeline, so gathering and analyzing backend uptime could easily piggyback on that existing investment
At an embedded software company, I wrote a availability meter in the web client that would allow the users (mobile operator technicians) know if their client is functional at a glance.
At another media company we used Pingdom but refactored to use Datadog synthetic. We learned the expensive mistake that Datadog’s synthetics are very powerful but also way more expensive for what we needed. At yet another media company we used Uptimerobot which generates stats about both availability and latency.
I also worked at a platform team where one team was responsible to build observability tooling using open source tech stack (Prometeus, Grafana, etc.) but that’s a case study for two other upcoming posts.
I even wrote my own little availability monitoring tool using AWS Lambda with a grand TCO of 0$/mo for monitoring 20 endpoints every minute. Maybe I’ll write about it in the future.
This article took about 8 hours to draft, edit and illustrate. If you enjoy it, you could support my work by sparing a few bucks on a paid subscription. You get 20% off via this link. My monetization strategy is to primarily keep the content free and only rely on donation to support the hours I pull from my private time to share insights. Thanks in advance for your support. You can also share this article within your circles to increase its impact. 🙌
> * What if the network connection is unstable or has jitter?
> * What if the client machine has performance issues?
I actually think both of these still are valuable to know about. Google's Gmail team discovered that the average loading time for Gmail was super high once they started measuring it from the client. They discovered that most of the clients were based in country with low-quality Internet with low bandwidth and jitter. While they couldn't fix the clients' network connection, they could still employ caching & retry policies etc.
When it comes to performance issues in the client, you _can_ still make your application less performance intensive - maybe even move performance-heavy from client to server.
Knowing how customers actually perceive the product is key. If you know the experience is sh*tty* when measure in the client and you can't do anything about it (ie. real-time video over a bad Internet connection), it might actually hint that you haven't built a viable product that works.