

Organization Architecture
The importance of organization design on service design and why consumer journey is the key to improve system reliability

The reliability of a service is directly impacted by the shape of the organization providing it. The shape, not the budget, headcount, or maturity level —as irresponsible leaders like to frame it!
This article elaborates:
Why does the shape of the organization matter for reliability?
How does it impact communication between teams and by extension interactions between the components of the system?
What insight can be unlocked with consumer journeys to create a healthy organization that builds reliable systems?
This is part 1 of a longer article about the pros and cons of different organization structures that I dubbed Smorgasbord, Kebab, and Cake! 😋
Organizational architecture
Just like software architecture, organizational architecture is about composing a whole larger than the individual components.
Similarly, organizations have emergent properties due to the interactions and dependencies between their parts. In simple terms, collaboration between people shapes communication between systems.
Software architecture is a graph. Org chart is a tree.
Collaboration is heavily impacted by the organization structure, reporting lines, delivery timelines, and the territorialism that our species still shares with other primates.
These are the mechanics of Conway’s law. And inverse conway maneuver cleverly takes advantage of them.

Many companies ship their org structure to the end user.
You’ve probably been through experiences that shape-shift between different steps of your journey. Sometimes, there is a benign transition like a screen flicker or UI change. Some other times, your journey just chokes at the point of handover between what appears to be built by different teams.
You learn a lot about the people behind a product just by using it.
On paper, the system fulfills the requirements. In practice, the sum of the parts is a negative experience!

The handover between teams has a higher impact than dependencies between systems.
But why is it so hard to design an organization based on the systems it produces?
The answer reveals itself once you take a glimpse at a system diagram and organization chart side-by-side:
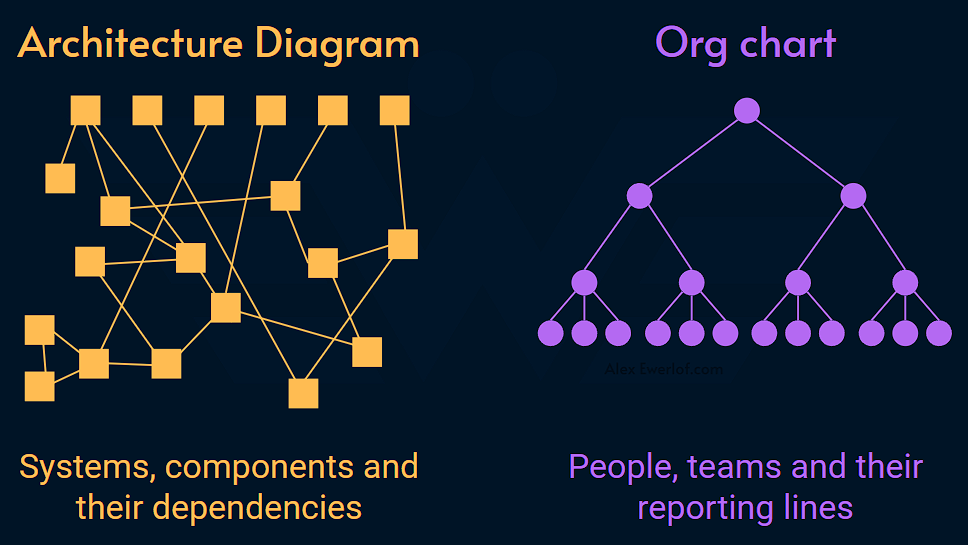
Note: the org chart above is too idealistic. The reality looks more like this:
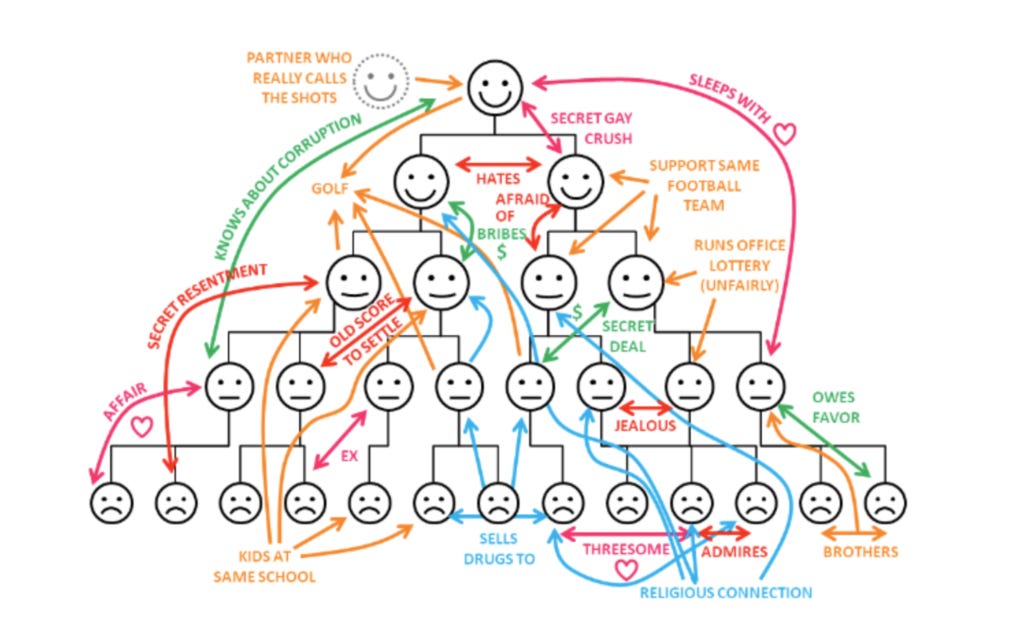
OK, maybe the captions are not ideal, but you get the idea. 😊Humans being human have their own diverse range of values, rules, and biases that directs who they trust, who they listen to, and who they avoid. That’s not new.
I’ve previously written about an example of this phenomenon for platform teams:

Software components often have dependencies that span across the formal organization. There are known dependencies, then there are unknown dependencies that grow over time. Then there are indirect dependencies that usually no one knows about until sh*t hits the fan.
Both the human side and the system side are very complex. An organization architecture is usually outdated before it is announced. That is one reason some companies are in constant reorg mode. To make it worse, many leaders don’t understand the J-curve that comes with every change.

The J-curve refers to the initial dip in performance or productivity as teams adapt to new changes. Constant reorgs accumulate the worst of those curves.

Macro-optimization
Too much has been written about how to improve the individual components of a service using TDD (test driven design), CI/CD (continuous integration and deployment), SRE (using software engineering practices for operations), refactoring, paying tech debt, and buying 3rd party tools (usually their sales pitch goes like “We take care of X, so you can spend more time coding”). 😄
And that’s fine. Good engineers want to build systems that they can be proud of.
However, these methods are micro-optimization with their own limits.
To significantly improve system reliability, we need to look at larger forces at play:
A system is not the sum of its parts, it’s the product of their interactions. If we have a system of improvement that’s directed at improving the parts you can be absolutely sure that the performance of the whole will not be improved. —Russell L. Ackoff (I highly recommend watching his 90 second video)
Poor organization architecture ignores these obstacles:
Every team dependency increases the risk of misunderstanding.
Every point of handover opens a miscommunication crack for things to fall into.
Every new process and role increase the risk of delay.
Every unclear or broken ownership is a vulnerability for the blame game.
Every incident starts a novel maze to figure out which team is behind what component and how to motivate them to own it and fix the failure ASAP.
There is always a good reason for the process but it’s never about empowering human ingenuity. It is about protecting against human stupidity.
The handovers, miscommunication, and lack of ownership show themselves in the following symptoms:
Lower velocity: a seemingly simple change takes disproportionally long time because the developers have to jump through hoops and do trial-error or in some cases reverse-engineer systems to get the job done.
Lower TBF: time between consecutive failures
Higher LT: lead time from when a change is made till it's available in production
Higher CFR (change fail ratio): changes to code, config, or content which break production
Higher TTR: the time from incident symptoms hit the consumer until the root cause is fixed (which is directly impacted by how hard it is to find the right team)
Higher impact radius: how far does one failure propagate
Higher incident cost: the negative impact of incidents on sales, potential revenue, SLA penalties, and company reputation
Higher manual to automatic incident ratio: the number of incidents that were discovered manually (either by staff or user reports) divided by the number of incidents that were discovered automatically (e.g., through monitoring, synthetic tests, etc.)
Higher false pages: the number of people that were paged mistakenly by the central incident team in order to find the right person who can fix the failure
etc.
Inferior quality and reliability are just the symptoms. The real root cause (no pun intended) is poor organizational architecture.
Leaving services to individual talent and managing the pieces rather than the whole make a company more vulnerable and creates a service that reacts slowly to market needs and opportunities. —Lynn Shostack, who coined the term Service Design in 1982
Weak leaders miss the root cause and work around it by adding more processes, people, roles, gate keeping, and friction to the mix hoping to improve system.
There is always a good reason for the process but it’s never about empowering human ingenuity. It is about protecting against human stupidity.
Adding headcount to improve delivery bandwidth is the biggest fallacy due to the extra communication bandwidth it requires:

Anyone who has worked at a large organization should be familiar with all the meetings, demos, infomercials, newsletters, mandatory training, all hands, etc. I have a dedicated post on a solution here:

People, process, tools, etc. all have a cost both in real money and time. However, a variation of the velocity, reliability, and cost diagram is [ab]used to justify the price tag. 🤦

Reorg after reorg, the theme stays the same:
When you talk to the engineering managers, they complain about “cat herding”, “running a kindergarten”, or “immature organization”.
When you talk to the product managers, they complain about feature teams (or feature factory as John Cutler puts it).
When you talk to the team members, they complain about micromanagement, gate keeping, and blame other teams.
When you talk to the C-suit, they sigh at the high operational cost, low productivity, and disproportional damage of incidents.
When you look at the tech landscape, you see a fragmented landscape that seems to contain every technology invented since Unix epoch. Someone may even naïvely throw a tech radar in there hoping to defragment the tech landscape to no avail.
When you look at the architecture, you see a tangled spaghetti where every component can potentially be connected to another component at various times.
When you check the incident vitals, you find lots of novel incidents that were detected manually, took a long time to fix, and caused unreasonably high damage to the business.
When you look at the total cost of designing, building, monitoring and maintaining the software, you realize that the org is too big for what it’s trying to achieve.
Disclaimers:
Before planning a layoff, please make sure to read till the end. Layoff is only an option if the company is unable to monetize the accumulated human capital it has already hired. It has long lasting negative effects.
If any of my current or former colleagues sees the above section as a rant, rest assured that I have seen variations of those problems at a dozen companies over the past 2 decades. One of my principles is to never complain unless I have a solution or am willing to be part of the solution. Hopefully, this post and the next post help.
Is there a way to improve reliability and reduce the cost of running the business without hurting velocity?
The key perspective to unlock the answer is the consumer journey.
Consumer journey
In the field of UX (user experience), a user journey is:
A scenario-based sequence of the steps that a user takes to accomplish a high-level goal with a company or product, usually across channels and over time. —Kate Kaplan
User flow is a related term but is more detailed, idealized, and typically concerned with one product or channel (see a comparison between these terms here).
User journey is primarily used when designing experiences towards external customers (e.g., end user of an app, website, or device).
I use consumer journey because:
It is a generalized term that applies to services that have internal or external consumers.
Internal service example: an internal infrastructure platform that is used by application developers.
External service example: a mobile banking app or your favorite 1-minute video story app. 😉
The word consumer is more consistent with the language we have built so far about services.
It is concerned with the high-level journeys as opposed to low level flows. The high-level view is more useful in the context of organization design.

There are two important things to note here:
The journey order is not always predictable. Example: in an internal platform product, a developer may first read the docs before provisioning resources while another developer may do the opposite
The journey may traverse interfaces. Example: in an external banking app, a user may request a new payment card without freezing an old one. Another user may start the journey on the web and continue on the mobile app. Yet another one may do the opposite.
Kebab vs Cake
This article scratched the surface for a follow up which talks about 2 common organizational architecture patterns, their pros and cons, as well as a pragmatic approach to use consumer journeys to design organizations that build reliable systems.
Read the follow up here:

My monetization strategy is to give away most content for free. However, these posts take anywhere from a few hours to a few days to draft, edit, research, illustrate, and publish. I pull these hours from my private time, vacation days and weekends. Recently I went down in working hours and salary by 10% to be able to spend more time learning and sharing my experience with the public. You can support this cause by sparing a few bucks for a paid subscription. As a token of appreciation, you get access to the Pro-Tips sections as well as my online book Reliability Engineering Mindset. Right now, you can get 20% off via this link. You can also invite your friends to gain free access.
Highly recommended for tech leads and CTOs, this insightful book on organizational architecture explores its implications in depth