


In the context of reliability engineering, service level indicator (SLI) defines how reliability is measured, and service level objective (SLO) sets the expectations.
But what exactly is a service?
Is it the same as system? Is it a microservice? A database? An app? An API? A ticketing system? None of them?
Do you even have a service to set a level on?
Here’s a clue: if you solve any problem for anyone outside your team or organization, you have a service level whether you acknowledge, measure, and communicate it or not.
This post offers a concrete definition for service with metaphors, examples, and illustrations. The goal is to enable you to set meaningful SLIs and reasonable expectations for your services.
Dictionary
Service (noun)
The action of helping or doing work for someone: “millions are involved in voluntary service”
Assistance or advice given to customers during and after the sale of goods. “They aim to provide better quality of service”
In simple terms:
A service is provided by one party and consumed by another
A service helps solve a problem or achieving a goal
Restaurant

Think of a typical restaurant:
The customers go to a restaurant to eat food. On the surface, food is the product. But good restaurants optimize for an experience: anything from presenting and serving that food to the utensils, chair, menu, music, location and even the bathroom!
Sidetrack: “if you want to know how clean a restaurant’s kitchen is, visit their bathroom! The part of the facility you can see is always cleaner than the parts that you can’t (e.g. kitchen).”
There are many roles that operate a restaurant: The cooks, servers, cleaning staff, cashier, the person who buys the ingredients, … Sometimes one person plays multiple roles, but as long as the job is done, most customers don’t really care. They’re primarily there for the food.
There is a lot of equipment that is used behind the scenes: cookware, fridge, knives, payment device, mop, etc. All of them contribute to how the consumers experience the restaurant.
To sum up:
Food is the product
Customer is the service consumer
The restaurant staff are collectively the service owner who own the service
The kitchen, furniture, etc. can be thought of as the components that are used to provide the service
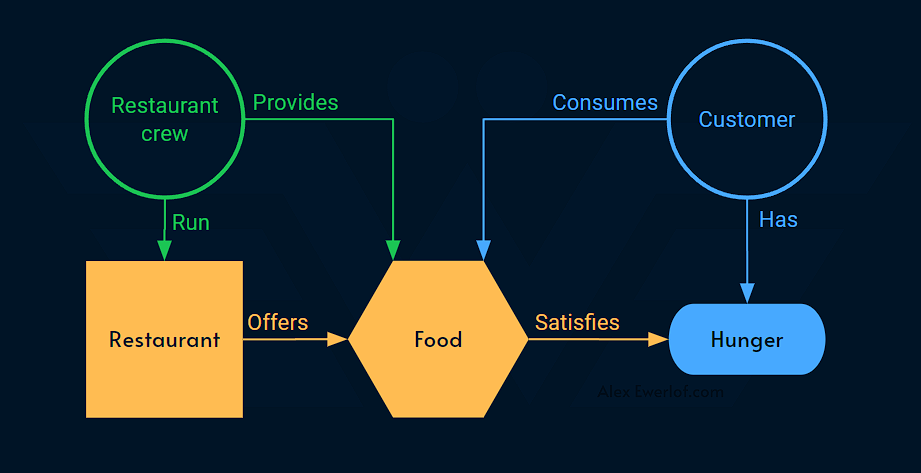
But what is the service? Is it the act of serving the food? Is it the service fee in the bill? 🤑
In a nutshell: Service is any solution to a consumer problem. It can be features, functionalities, capabilities, or other types of interaction like support and governance. Service is what creates value for the consumer.
The meal is part of it, but the real service that the restaurant offers is the experience of eating a meal. Many restaurants don’t understand that (😄the ones with dirty toilets! 🚽) but the ones who do, care about improving their service. They meticulously optimize any customer facing surface and interaction down to details because they realize that CX (customer experience) is king.
Using more formal terms, we get this:

Restaurant service level
Before we shift gears and use this metaphor in systems engineering, there’s a couple of important detail to cover:
Service level is how each service is perceived from the consumer’s perspective.

The emphasis here is on perception from the consumers’ point of view. For example:
The cooked meal should match what was promised on the menu and any customizations requested by the customer
The seats should be comfortable enough, the utensils should be clean, the washroom should be tidy, the music should be pleasant, the payment method should work, location should be accessible, etc.
The interactions with the customer should be pleasant so that they are positive about coming back again, etc.
Notice I didn’t say anything about the price! Service level is about creating value that is worth the price. That’s why there are cheap restaurants and expensive ones. Cheap restaurants generally don’t go above and beyond (e.g. with a valet service).
Your service level objective (SLO) should match the budget dedicated to the service. Ignoring that fact can easily lead to premature optimization (because of the 10x/9 rule).


Ignoring the perception from the consumer’s point of view is by far the most common pitfall when implementing service levels.
It’s like measuring food temperature upon serving (or even worse: when in storage) and call it a service level! Sure, it’s important, but once we identify the service, we should find metrics that aggregate those variables as part of something bigger: customer’s perception of the service level.
There are many aspects of running a restaurant that’s abstracted away from the customers. For example: the cookware, brand of the Wi-Fi access point, price of the energy used to cook the meal, name of the internet service provider (ISP), etc.
The point is: anything that doesn’t strongly impact a customer’s experience in a meaningful way is not a service worth setting a level on. Any of these aspects can affect the customer facing services, but as far as the customers are concerned, they are implementation details.
The point is to set the service levels on a black box, not a white box.
Black Box: refers to a system or component being tested solely based on its inputs and outputs, without any knowledge of its internal workings.
White Box: is the opposite. You’re aware of the internal components of the system you are testing.
Service levels are set at the boundaries of what the service owner offers to the consumers. There’s a good reason for that as we discuss in a moment!

Aligned autonomy
Most people want autonomy! They don’t want someone micromanaging them and telling them WHAT to do or HOW to do it. Bosses, on the other hand, want efficiency and alignment.
Most engineers don’t want their consumer to dictate WHAT they should build. They want to know WHY the consumer wants what they want. With service levels we measure HOW good the solution is performing.
WHAT goes on inside the system architecture is no one’s business! Externally at least.

Service levels are great tools for aligned autonomy. They set quantified key metrics that the team will be accountable for while given freedom to solve the problem as they see fit.
I know the “no one’s business” part is a trigger word for the control freaks and those who are genuinely wondering if you can trust people to do the right thing without any control, process, or standard.
May I suggest a different perspective?
Process is always put in place for a good reason and it’s never about empowering engineers. It’s about protecting against human imperfections: errors, forgetfulness, inaccuracies, malice, compliance, etc. Process is friction: you can use that friction to your advantage when it is needed (e.g., to make it hard to “accidentally steal” user data). With service levels, we replace most processes by setting expectations by measuring what the consumers care about (SLI) and let the team decide how to meet the expectations (SLO).
Best practices are often someone’s interpretation of what worked in a given environment for a specific goal and point in time. What big tech is willing to communicate publicly in conferences, white papers, and blog posts isn’t how their entire company works all the time. With service levels, you treat the teams as adults to build their own best practices based on the expectations and the experience of running their specific services.
Standards are a great way to reduce cost and duplication of effort while accelerating decision making. Unfortunately, the entity emitting the standard is often not the same entity who should do the work (migration, refactoring, purchasing, etc.). As a result, premature standards get in the way and cause unnecessary friction. With service levels you give the freedom to the team to pick the right tool for the job instead of using a hammer because all the other tools are blacklisted in the “standard”.
Services in reliability engineering
A good way to identify services is to think about service levels because that requires seeing your systems from the consumer’s perspective.
There are many metrics to measure various aspects of a product, system, or team. Not all of them are service level indicators. SLIs are metrics, but not all metrics are SLIs. See a previous article for some good and bad examples.

In reliability engineering, we’re primarily interested in reliability metrics. More specifically, the metrics that tell how the consumer perceives reliability.
Performance metrics are only relevant when there’s a risk attached to them. The reason (as we discuss in upcoming articles) is because SLIs tie to SLOs to set expectation. That expectation should be tied to accountability. A good way to formalize that accountability is alerting.
In a future article we distinguish between critical and diagnostic metrics but in a nutshell:
Critical metrics are the ones that are worth to tie to an alert and wake up the on-call person to fix it (SLIs)
Diagnostic metrics are the one that go to a dashboard so you can use them to find the problem after the alert wakes you up (everything else)
If a metric isn’t worthy of declaring an incident, it is not a good service level indicator.
A provider that isn’t worthy of having a SLI either doesn’t have a consumer facing service or isn’t that important.
The service is often offered by consumer-facing pieces of the architecture:
An API for generating text or fetching images
A UI to generate reports from data
An application that finds the cheapest restaurant
A platform that allows running Kubernetes pods
An observability solution for gathering data in runtime
A build pipeline tooling that can be used to build applications
An online support solution that enables the customers to troubleshoot problems with their product
…Any piece of technology that solves a problem for some consumer
The service only gets its meaning from its usage (consumption) to solve a problem (for service consumers).
Now here’s something to think about: a team may solve problems manually with limited or no technology!
Manual services
With our definition, service levels are not limited to systems but cover any entity that provides the service. The team may provide some services too.
For example:
Infrastructure provisioning and governance (e.g. DNS governance, issuing certificates, etc.) They may or may not have a process or automation, but often there’s some human involvement that distinguishes the service from a say, API call.
A central team that handles incident triage to protect the other teams from alert fatigue
A team that provides security, compliance, audit, and education services to the other teams or companies
When I am doing the service level workshops, I always encourage the teams to think about their services holistically, not just systems.
Why does your team exist?
What problems are you solving and for whom?
Why is the company paying you?
Many teams provide services that are manual but are critical enough to measure with a SLI and set an expectation with a SLO.
The reason is that once you start measuring those manual services, you may realize that they consistently fail the expectations, and something has to be done:
Lower the expectations and be more realistic
Automate what can be automated
Step back and question the manual work: if it is getting in the way, maybe there’s an opportunity to rethink the flow
The point is: manual services are also services. Services are not exclusive to systems and code.
Immediate consumer
So far, we’ve covered simple cases where the service consumer is the end user (e.g. the restaurant customer is at the top of the food chain —no pun intended!).
When it comes to systems engineering, that’s often not the case. Your consumer is using your service to offer another service, which in turn will be used by their consumers.

In the context of service levels, we’re only concerned with the immediate consumer: the ones who use your service.
So, the question is: who cares about the consumer’s consumer —or any indirect consumer for that matter?
The answer is: it is up to your immediate consumer to identify the metrics that you should be responsible for.

We showed an example of this trickle-down model in a previous article:

Organizational services
This is where things get interesting and very meaningful.
There’s nothing in the service level description that dictates it to be an engineering concept at the team level.
One of the most common pitfalls of implementing service levels at large organizations is failing to map accountability to reliability. More specifically:
The accountability exists in the chain of command of an org chart (tree)
The reliability exists in the interactions between the components of a service (graph)
So how do we map a graph to a tree (and vice versa)?

In a future article we’ll talk about how to map the graph to the tree (there are multiple ways) but for now I just want to highlight that service levels are not just a team concept but can (and should) be used at different organizational units to make service reliability a first-class concern across leadership.
It is only then that the rule of 10x/9 can be meaningfully applied with discussions about budgeting, reasonable expectations, and true ownership.
My monetization strategy is to give away most content for free. However, these posts take anywhere from a few hours to days to draft, edit, research, illustrate, and publish. I pull these hours from my private time, vacation days and weekends. Recently I went down in working hours and salary by 10% to be able to spend more time. You can support me by sparing a few bucks for a paid subscription. As a token of appreciation, you get access to the Pro-Tips section as well as my online book Reliability Engineering Mindset. Right now, you can get 20% off via this link.
If you have feedback or questions you can comment.
