

SRE Archetypes
Different hats that SRE's wear in the industry: Admin, Architect, Toolsmith, and firefighter

It’s been 21 years since Ben Treynor Sloss coined the term SRE (Site Reliability Engineer). In a nutshell, SRE is about using software engineering practices in operation. For example, use automation to reduce toil, and use better measurements to reduce alert fatigue. There’s more to that but SRE is what you get when you put software engineers in charge of shipping what they build.
In an interview, he mentioned that people from 2 seemingly different backgrounds become SRE:
Sysadmins: people who are savvy at handling servers, networks, firewalls, and infrastructure.
Developers: people who have a background in building and evolving software products.
He then goes on to add that ideally he’d like to hire 50/50 from these two profiles. In this article, we’ll use 2 different lenses to group the SREs into 4 archetypes.
Disclaimer: no AI is used to research, create, edit this article. The core idea comes from talking to various directors and staff platform engineers across the industry.
The raise and fall of SRE
SRE remained primarily an internal secret sauce at Google until the Google Cloud marketing team brought it to mainstream:
Google launched a dedicated website with a great domain: sre.google
Subsidized and released 3 excellent books on the topic for free.
This was part of their marketing strategy to demonstrate know-how and earn the trust of new customers. It was simultaneously the first time the wider software industry got an in-depth view into the challenges and solutions of running planetary-scale services at Google.
As soon as the industry adopted SRE, new problems started to emerge due to the delta between Google and most other companies:
Budget: To begin with, Google has practically an unlimited amount of money. Where most companies lift-and-shift their workload from on-premise to the cloud to save costs, Google has the budget to build data centers across the planet.
Talent: Another side effect of having billions of dollars at their disposal is a high recruitment bar and competitive employee branding that attracts the best talent across the industry. The majority of companies benchmark their salaries and in the rare occasion that they hire top-talent, they have difficulty keeping them or monetizing their skillset.
Scale: Although the items in this list are tightly related, it’s worth calling out that Google solves planetary-scale problems, from search to email to office suit, the sheer scale of Google products call for different way of solving the problem. Anyone who had to design a system for a 1 req/sec vs 1M req/sec backend knows that the way you design and implement a solution is fundamentally different at different scales.
I like to use this analogy: Google’s version of SRE is like a cookbook for 3-star Micheline meals but most companies have more urgent things to do:
Some companies start building the kitchen (e.g. platform engineering)
Some others start buying the ingredients (e.g. outsourcing)
Others start growing chicken and plants for the ingredients (e.g. bespoke solutions often using open-source tools)
I’ve been an SRE at different capacities (Senior, Staff, and Senior Staff) at 3 companies. Over the past 25 years, I have worked with other SREs, DevOps, Architects, Infra, and SysAdmins at over a dozen companies. I also write about SRE and mentor a few talented people in this field.
In my observation, there’s a difference between the ambition and the day to day tasks at a given team, company, industry. Moreover, the people carrying the role have diverse way of working, preferences, and biases. Add the career ladder, organization topology, and team size to the mix and it’s very hard to tell what a role really does.
This article takes a different approach by defining a set of SRE archetypes and concludes with a set of tenets that apply to all those archetypes.
Archetype (noun): the original pattern or model of which all things of the same type are representations or copies —Mirriam Webster Dictionary
Let’s step away from theory and see how the SRE role is pragmatically implemented at different companies.
4 archetypes of Site Reliability Engineering
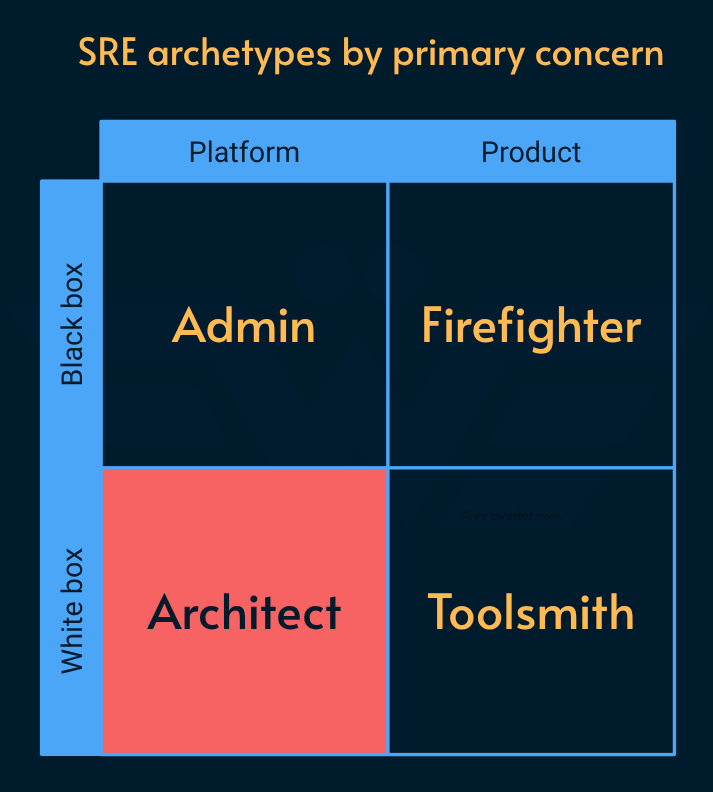
In general, SREs can be grouped in two axis:
Product/Platform: Do they focus on how the product solves a user problem or are mainly concerned with what’s running the product?
White/Black box: Do they fully understand (and/or care) what’s inside the box they’re running or not?
Note: There’s a nuance there: I believe platform should be treated as a product, even if you’re not working for a Platform as a Product (PaaS) company. Also these are more like ends of an spectrum.
This gives us 4 archetypes:
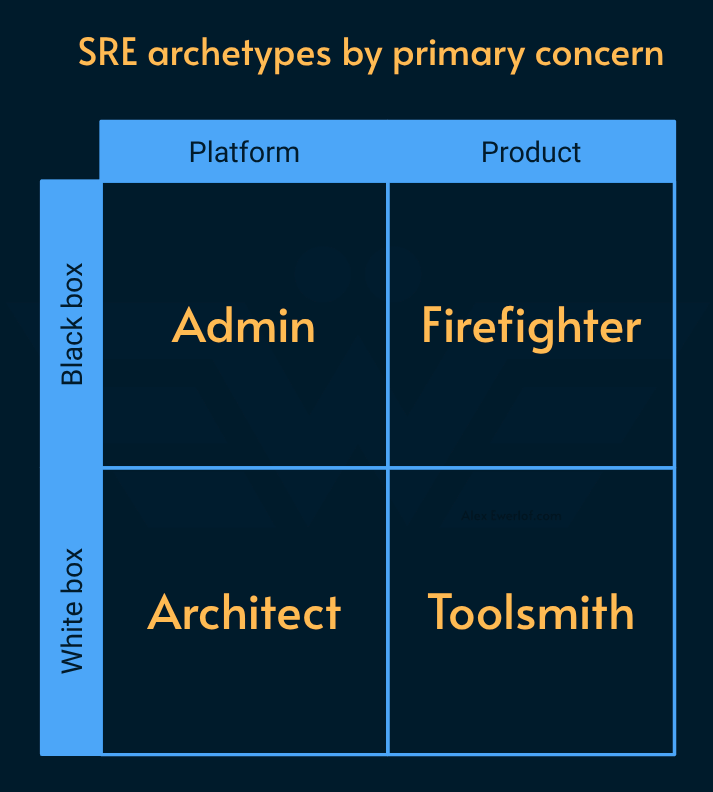
Think of these archetypes as “centers of gravity” for the majority of the day-to-day tasks. An individual may put on different hats at different times or sometimes at the same time.
Admin
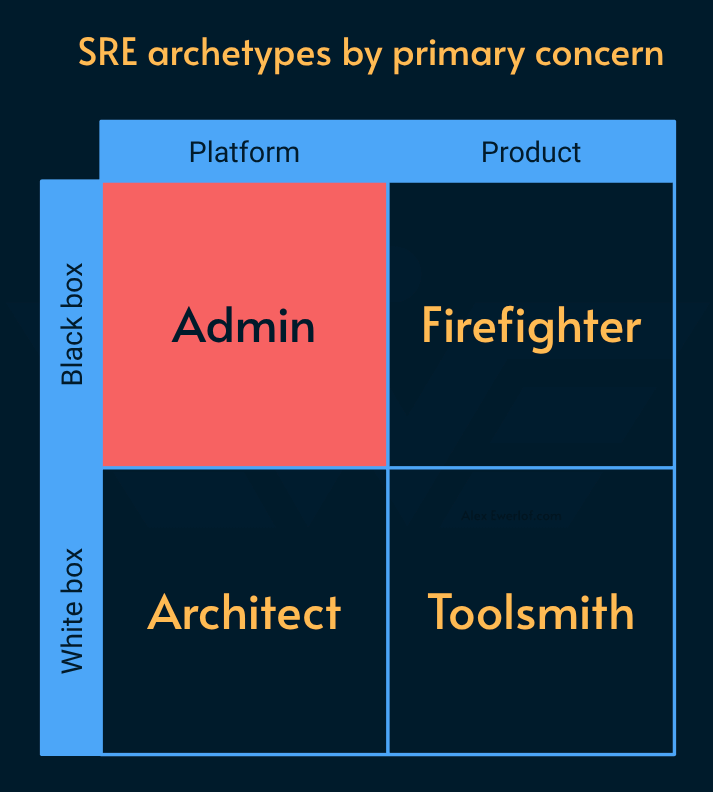
Provision and maintain on-prem or cloud infrastructure (e.g. Kubernetes, CDN, Observability stack, secret management, network topology, etc.)
Manage third party tools and contracts (e.g. AWS, GitHub, Datadog, Cloudflare, etc.) as well as access control and integration to enterprise SSO (single sign-on) solutions.
Optimize resource usage and cost efficiency across the infrastructure and platforms (also known as FinOps).
Some degree of coding using scripts, IaC (infrastructure as code), and configurations for resource management and automation.
Firefighter
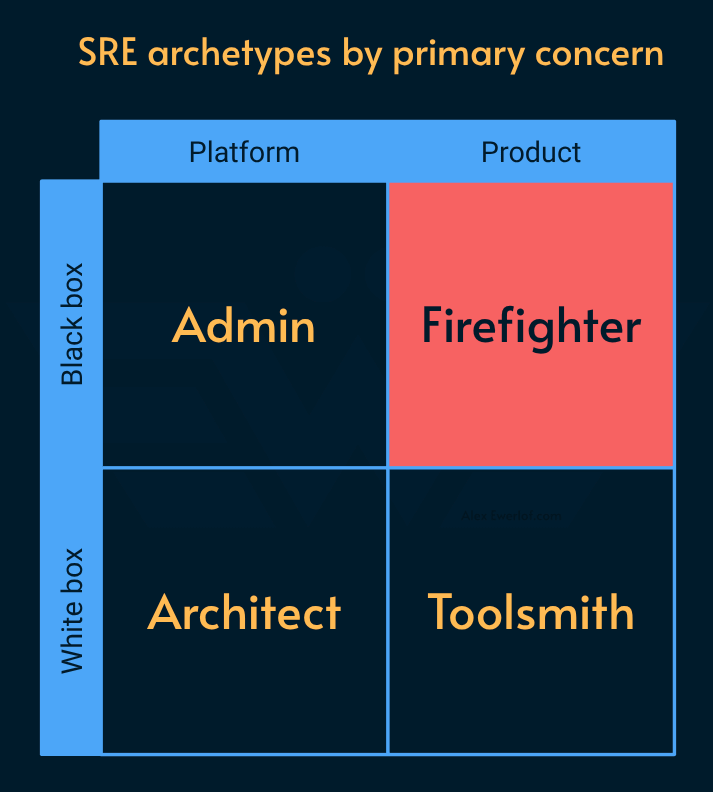
Own the PRR (product readiness roadmap) for teams that want to use SRE services as well as the incident management (IcM).
Help set up the on-call process, tooling, and rotation for product teams that need it and put them in charge of the code they develop. You build it, you own it.
Monitor resources (e.g. observing the cluster behavior) to identify anomaly and trigger alerts.
Take SOP (standard operating procedure) mitigation actions (e.g. restarting services, emptying cache, debugging credential/certificate issues, etc.). This is different from traditional NOC (network and operation center) because SREs are software literate and can reason about system behavior and mitigate some risks themselves. Moreover, as we see in the Toolsmith archetype, SREs use automation heavily to eliminate toil (repetitive, manual work that does not require a lot of creativity or problem-solving skills).
Note: alert fatigue is demoralizing. Firefighting should only be used to prevent things falling between the cracks. For example:
When there were no alerts for the incident (novel incidents). SREs may do the triage for such incidents (validate the incident, assess priority, and assign the right team).
When the alert pages the wrong team (alerts are set up on symptoms that is in owned by one product team, while the root case may be in another team). The SRE has deep architectural knowledge about system dependencies and may help find or delegate to the right team.
When the alert is orphaned and does not page any product team or the product team’s on-call persons are not accessible.
When the user impact is so significant that it requires involving legal, security, or public communication for formal stakeholder communication. MIM (Major Incident Handler).
Even in those cases, you need to eliminate the need for firefighting as much as possible. A good metric to measure is the percentage of incidents that were handled without the need to involve the central SRE team.
Toolsmith
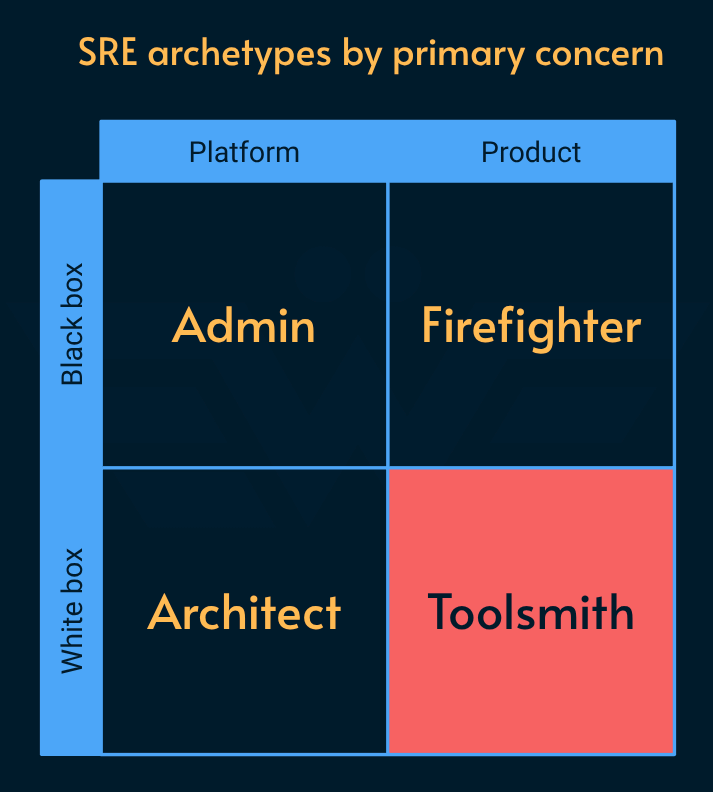
Reduce cognitive load for the product teams, improve developer experience (DX), and optimize self-service where developers can directly get work done without having to go through people. “Platform Engineering” is often a term that’s used to describe this archetype. The platform in this context is any bespoke solution that’s built on top of external infrastructure providers (e.g. what you get out of the box from Azure or your HP rack) to streamline the needs of the product teams.
Help instrument the observability tooling and build bespoke dashboards and service status page based on the needs of the organization for visibility, transparency, and reducing MTTD (time to detect an incident).
Implement and run automated E2E (end-to-end) tests against production services to detect any significant user-facing issue before someone has to pick up the phone and call customer support.
Implement the “golden path” for reducing friction when provisioning new services, as well as maintaining systems at scale (e.g. patching base images across all services through central platform).
Identifies toil (repetitive, manual work that does not require a lot of creativity or problem-solving skills) and automates it. For example: load testing, QA test frameworks, resource provisioning, as well as repetitive mitigations that firefighters execute.
Architect
Take part in designing new systems based on the NFR (non-functional requirements) for reliability, scalability, and security. For example, prevent cascading failure, add fallback or failover, implement graceful degradation, and ensure business continuity while maintaining key system functionalities.
Observing system behavior and troubleshooting code to identify performance and reliability bottlenecks and improve code and architecture.
Risk assessment and working with product teams to clarify ownership and accountability for their systems. Help set impactful SLIs and reasonable SLOs to establish formal measurable contracts between teams, stakeholders and dependencies.
Establishing standards and helping the teams to migrate to common solutions to reduce cognitive load, operation costs, and business risks.
Coach product teams to take full ownership of their products and build a reliability engineering mindset. Work with leadership to fix broken ownership.
These archetypes are not cookie cutter roles. In reality, a single SRE may fit into multiple archetypes and at different times depending on the needs and skills.

Notice that DevOps isn’t an archetype. That’s because DevOps is a set of principals not a role for one person. It involves elements of culture-building, education, tooling and organizational architecture. In practice, all the archetypes contribute to those concerns to implement DevOps.
Tenets of SRE
What connects all 4 archetypes of SRE are a set of tenets that is more or less common across the industry:
Apply software engineering practices on operation. SREs are software engineers. They are expected to understand and contribute to system architecture and code.
Eliminate toil (repetitive, manual work with low cognitive load) so that engineers can focus on more important tasks.
Instead of unrealistic expectations for the systems to never fail, SREs pragmatically identify how failure is perceived from the consumers’ point of view (Service Level Indicator) and what is a realistic level of commitment (Service Level Objective). This provides an error budget for each system to fail within accepted thresholds as well as setting alerts on what impacts the users.
Reduce cognitive load through improved tooling, DX, and education to put the teams in charge of their product.
Culture building and education to build reliability engineering mindset. Reliability is not something that one role can address alone. It requires a synergy between product and platform teams as well as awareness and support from the leadership.
You cannot fix organizational problems with technical tools, and sometimes it takes years to implement a proper SRE strategy.
My monetization strategy is to give away most content for free but these posts take anywhere from a few hours to a few days to draft, edit, research, illustrate, and publish. I pull these hours from my private time, vacation days and weekends. The simplest way to support this work is to like, subscribe and share it. If you really want to support me lifting our community, you can consider a paid subscription. If you want to save, you can get 20% off via this link. As a token of appreciation, subscribers get full access to the Pro-Tips sections and my online book Reliability Engineering Mindset. Your contribution also funds my open-source products like Service Level Calculator. You can also invite your friends to gain free access or save via a group subscription.
And to those of you who already support me, thank you for sponsoring this content for the others. 🙌 If you have questions or feedback, or you want me to dig deeper into something, please let me know in the comments.