


Service level indicator (SLI) is defined as the percentage of good divided by valid:
There are two types of Service Level Indicators based on the definition of what good looks like:
Time based: measures good time (uptime)
Event based: measure good events (failures)
This choice has huge implication on how you do error budgeting.
This article talks about these two types of SLI with some examples and when to use which.
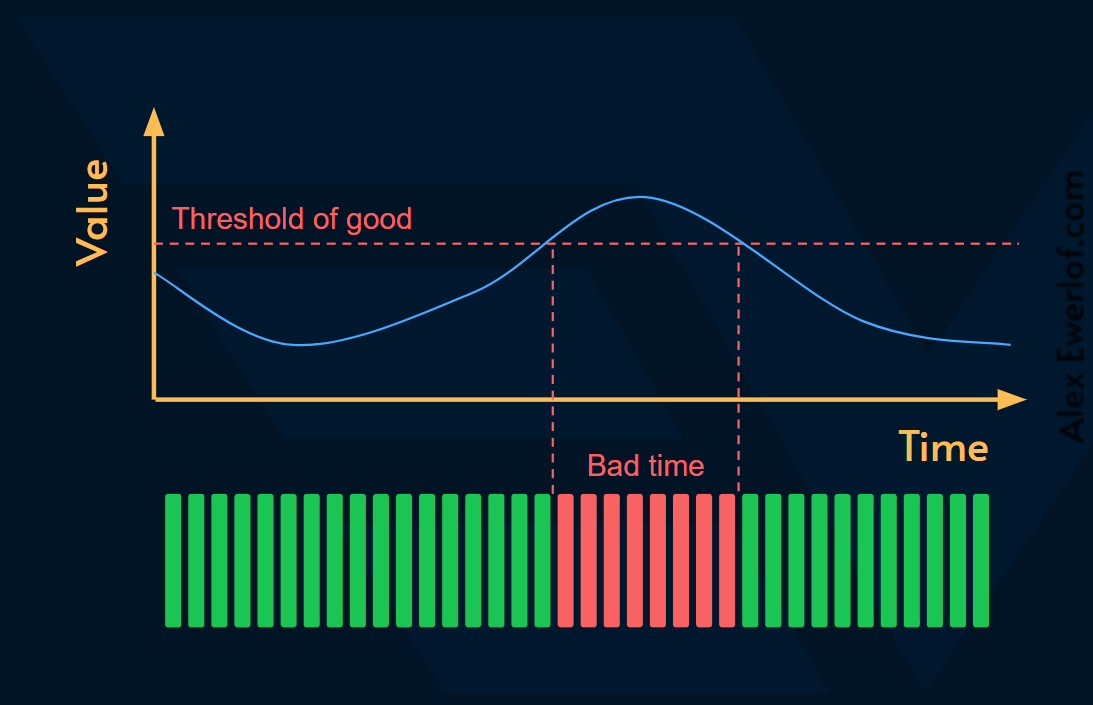
Time Based
Time-based service level indicators measure the percentage of time that the system was behaving good.
The focus is on the time period where the system was behaving correctly.
Although the definition of SLI allows being more specific, usually the valid time is the entire measurement window. In other words:
Time slice
Although, it is possible to calculate the good time down to any precision, Time-Based SLIs often count the number of good time slices (e.g. number of good minutes in a month). That way the formula looks like this:
The length of the time slice defines the granularity of the measurement.
If there are multiple data points in a given time slice, they need to be aggregated to calculate the good/bad status of the time slice. There are many aggregation methods:
Sampling: just take the data point in the selected time slice
First value: take the first data point
Last value: take the last data point
Random value: take a random data point as a representative of the whole time slice
Average (mean): calculate the average of all data points in a given time slice
Min: take the data point with the smallest value in a time slice
Max: take the data point with the largest value in a time slice
Range: calculate Max - Min
Mode: find the most frequent value
Percentile: sort the data points in the time slice based on their values values, then pick the data point closer to the P% of the length of the data set
P99: select the data point at the 99% index (e.g. if there are 612 data points, P99 is the data at position 605 in the sorted data set)
P50 (Median): select the data point at the 50% index. This means 50% of the data points are larger or equal than this data point and 50% are lower or equal to this data point.
...
Count: count the number of data points in a given time slice
Sum: add the value of all data points in a given time slice
Rate: calculate the ratio of the number of data points that match a criteria from all the data points in a given time slice
Stddev: The standard deviation is a measure of how the data is scattered around the mean (average). It has the same unit as the data point value.
Stdvar: The standard variance is the squared average diff from the mean (average). The unit is the square of the data point value unit.
Topk or Bottomk: select the top (or bottom) data points in a data set that is sorted in ascending order.
Note: some platforms call this functionality rollup (e.g. Datadog) while others call it aggregation (e.g. Grafana or Elastic).
Example
Suppose we have a database and decided to use the query response latency as SLI with a time slice of 1 minute. If the P75 percentile of the data response latencies in a minute is above 1000ms (threshold of good), we consider that entire minute a failed time slice.
This is an example of our data points:
Pros
Time-based SLI is easier to measure
Uptime is a bit more intuitive to understand
At any given point in time, it’s easy to calculate the remaining error budget (e.g. How much downtime is remaining for this month?)
Time-based SLIs are not sensitive to the amount of load (number of data points in a time slice is aggregated anyway). This means a time-based SLI is a good choice for systems that don’t get too much traffic. On the flip side, time-based SLIs are more forgiving to failures due to a spike in load (as far as the SLI is concerned a minute failed during the night is as significant as a minute failed during peak hours). This property may not be desired.
Some SLIs are time-based by nature. For example, percentiles are used to focus the optimization on outliers. Percentile is calculated for a range of values over time (e.g. 5 minutes), which fits perfectly into the concept of time slices. You can also calculate the percentile over the entire SLO window (e.g. P99 of all response latencies in the past 30 days) but this is not the time-based SLI we are talking about. It’s event-based as we’ll get to.
It is easy to tell the current status based on the recent data. That is because the status of each time slice is calculated separately. You don’t need to aggregate the data through the entire window in order to calculate the current SLS (service level status).
Cons
Unless the system receives a uniform load (i.e. ~200 req/sec for the entire month), time and impact may not be correlated. For example, if the system was down for 30 minutes due to heavy demand right after launching a new product, this disruption is considered as serious as 30 minutes in the middle of the night when most users don’t use the system.
A few bad events can easily hide in an aggregation period and go under the radar. For example, if the average latency in a minute is in the “good” range, there can be requests in the same aggregation period which their latency in not in the “good” range. For these cases it is better to use percentile.
The time-based SLIs usually miss the notion of working hours and assume a global 24/7 service. This doesn't make sense for some products. For example, if a product is supposed to be used only during working hours in a certain time zone, it doesn’t make too much sense to have on-call during night and weekends. As we’ll see in an upcoming article, this is not a show-stopper because the alert notification can be decoupled from the failure detection. In other words, the system can be down outside office hours and the alert can only trigger during the office hours.
Excluding planned maintenance windows from time-based SLIs can be complicated.
In 🔴alerting on SLOs we’ll discuss how the speed at which we consume our error budget (burn rate) will be used to trigger an alert. Time-based alerts will have to look back at the predefined time window (based on the burn rate) to detect an incident. This makes the alerts too slow compared to event-based SLIs which trigger as soon as a good/valid ratio drops below the SLO.
Event Based SLI
The focus is on the number of good events divided by the total number of events.
In the same example as before:
Example
Let’s reuse the previous example. Suppose that for a database we have decided to use the query response time as SLI. We define a threshold (for example one second) and any individual query that takes longer than one second to response is considered bad.
The diagram below shows the total number of events over time. It changes as the demand for our system fluctuates.

Event based SLIs are interested in the percentage of good events from valid events.
Pros
They automatically adjust to the amount of load
Better map to impact. If 10x more requests got error in the same amount of time, this affects the SLI and error budget 10x.
In 🔴alerting on SLOs we’ll discuss how the speed at which we consume our error budget (burn rate) will be used to trigger an alert. Event-based SLIs will adjust automatically if the error budget is consumed faster than predicted. For example, if the error budget is being consumed at the rate of 1000x, the event-based alert will quickly pick it up.
Cons
Unlike time-based SLI, it is hard to tell the status based on recent data (there’s no time slice). We need the data for the entire evaluation window.
It is harder to reason about the error budgets for event based SLIs.
It is more punishing the team when a high number of bad events happen in a short time and can practically burn the entire error budget. One could argue that that these spikes in load are exactly why we’re measuring service levels in the first place.
Conclusion
Which one you pick boils down to a few question:
Is the reliability perceived as good time or good events?
Does the service consumption pattern vary a lot during time? For example does the load drop significantly during the night or weekends? Do you get massive spikes in high season? This means different time slices have different impact and an event-based SLI suits better.
Time-based is less punishing for the team when incidents happen during high traffic.
How should the error budget be formulated?
Time-based SLIs consume the error budget based on the duration of bad time
Event based SLIs consume the error budget based on the proportion of bad events1.
Do you want easy math? Time-based has easier in calculations.
Do you want to know exactly how much error budget is remaining at any given time? Event-based SLIs don’t give an accurate estimate of the remaining error budget if you can’t predict the future load.
Do you want the SLI to map to the impact? Event-based is more accurate and maps better to the impact. It considers the impact of low/high load and spikes in the load.
References
Request-based and Window-based SLIs (Google Cloud SLO Monitoring)
SLI Types (IBM Instana Observability)
SRE fundamentals: SLIs, SLAs and SLOs (google cloud blog)
Uptime.is: a simple uptime calculator
If there only 2 types of SLI metrics, namely event and time based SLIs, from which we can derive availability SLO. Does it imply that there are also only ever 2 types of Availability metrics ?