

Introducing Service Level Calculator
An interactive visual tool to learn about service levels, set meaningful SLIs and reasonable SLOs as well as alerting

Note: the 🔴 red circles mark the articles that are to be published. As they are gradually published, they will be linked.

At my current job, I’m responsible to help over hundred teams to set their Service Levels:
Choose meaningful indicators (SLI)
Set reasonable objectives (SLO)
After an introduction session, we go to a 🔴 workshop where we systematically find the answers those two questions.
Some of the early learnings were:
These abstract concepts can be hard to pick up for someone new. However, you don’t have to be a SRE (site reliability engineer) to understand these topics. In fact, in a full ownership setup, it is everyone’s responsibility to measure the right thing and commit to it
Math can be daunting and time consuming using a generic calculator. There are some tools dedicated to the calculations of service levels but they’re either primitive, or way too complicated to serve as a learning tool.
I needed something that is:
Easy to use and understand visually while allowing interactive play
Come with lots of inline help to serve as a learning tool in compliance with Google’s excellent books
Doesn’t cost me to run
And so, SLC (service level calculator) was born 🎉

In a nutshell, Service Leval Calculator is an OSS (open source software) SPA (single page application) that runs in the browser (responsibe design).
It is primarily intended for engineering teams, product managers, and engineering leaders who want to progressively find an answer to questions like:
What type of metric should we measure?
What is a good objective for that metric?
How much is the cost of the error budget?
When should we trigger an alert when the objective is being breached?
…
All of that in an interactive manner. The idea is to let the user tweak things and let the UI update in real time.
Quick introduction to UI
A common pattern that you see throughout the UI is those tiny “learn more” links which expand in place to explain more about a specific parameter or aspect of service levels:

They may contain links to articles in this blog and my book Reliability Engineering Mindset.

At the top of the screen, you can see a list of examples which you can load to populate the UI:

These come from our Service Level Workshops as well of various sources like Google SRE books. The full list of examples are on Github and will be added as we come across more interesting cases.
At the bottom, there is a share link that updates in real-time. You can copy the link to both save what you’ve come up with and also share it with colleagues and stakeholders:
The rest of the UI is grouped into 3 groups each containing the decisions that you need to make for that particular aspect of service levels:
1. SLI
This section starts with a title and description (useful when sharing the link) as well as the most important decisions you need to make for an SLI:
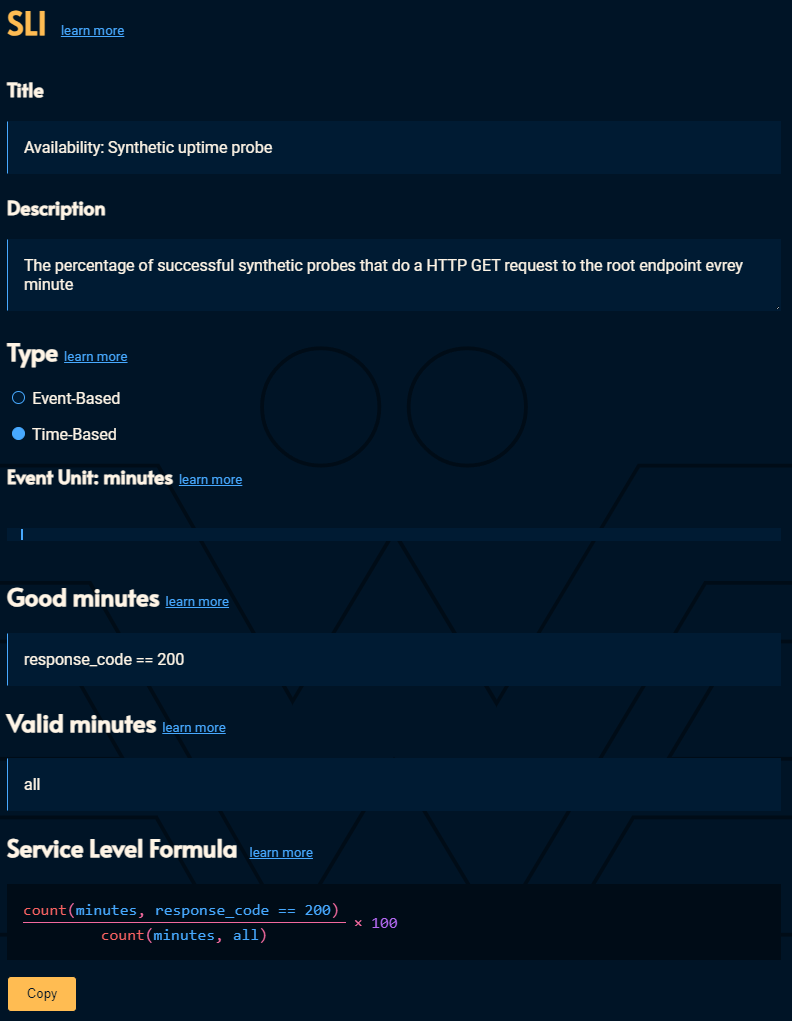
It ends with a normalized formula for SLI that can easily be copied as plain text to your tool of choice.
2. SLO & Error budget
The SLO and error budget complement each other, therefore they’re in the same section in the UI:

Again, you can see the parameters for SLO and Error budget:
The SLO value (there are 2 sliders to allow fine-tuning the exact value as you’re keeping an eye on the error budgets and their cost)
The compliance period, also known as window. Note that you can expand the “learn more” section for pre-defined values.
Cost of error budget: now this part may be new, but due to common request from product managers, SLC allows associating an average cost to a single failure to be able to calculate the cost of error budget in financial terms that is understandable by business stakeholders.
You can play around with the numbers and controls in this section to define a SLO that exactly matches your needs.
3. Alerting
This is arguably the most complex part of SLC and one of the main reasons that I wrote this application in the first place! 🫠
Throughout my career, I have always set alerts on thresholds for critical metrics. However, Google SRE books recommend alerting on SLOs. It makes total sense because if SLO is the team’s commitment towards another team, of course the team needs to be on top of their metrics using automatic alerting.
Alerting on burn rate (the rate at which error budgets are consumed) is simple at a high level but complex when you go about implementing it.
Since I had no experience with it, I had to read the SRE Book Chapter 5 multiple times to fully grok it and write this part of the app.

The timeline in that section is interactive and allows adjusting different parameters. You also have the option to use short-window alerts (by default it is hidden to not clutter the UI).
I will do several follow up articles and link them in the “learn more” snippets of the UI about 🔴alerting on SLOs.
How can you support me?
This application easily took over 150 hours of my time so far to create and as I said a few articles need to be written to unpack its more complex aspects.
If you like this application, you can buy me a coffee or even better: a subscription to this newsletter which grants you free access to my online book Reliability Engineering Mindset. Right now, you can get 20% off via this link.
The full source code is available on Github under the permissive MIT license, so feel free to copy, tweak and make it your own.
All I wanted was to create an educational tool to help me facilitate the service level workshops, and if it helps others, it’s a bonus. 🎉
👉 I’d love to get feedback: Show HN: Service Level Calculator – An education tool for SLI/SLO/error bugets.
You can also create an issue on Github or give anonymous feedback via Google forms.
Please share this post in your circles to spread the word and let more people discover this tool to save time and self-onboard to service levels! 🙌
Love this tool. Thinking to use this as educational within the SLO workshops.
Not an engineer but sense this may interest the engineers and product developers I know, and will be sharing to Credtent.org, Abacor.com and 360sierra.com
🙏🙏🙏