

Mapping reliability to accountability
Holding engineering leadership accountable for the reliability of engineering artifacts

I have spent the past 2 years rolling out Service Levels across a large organization (110+ teams). During this time I sat down with the majority of those teams face to face to identify their service, methodically discover their reliability metrics (SLI), and set reasonable expectations (SLO) and take steps to establish full ownership.
My focus has been the teams at the leaf nodes of the organization tree:

That is just the surface area for improving reliability. Knowing that your tech isn’t good is not going to help if the leadership is not on board with investments to improve it.
Moreover, the team dependencies across the org create gray areas where there isn’t clear ownership over SLO breaches.
To fix some hairy problems, we had to bring leadership onboard and work in the depth of the organization tree.
This post is about a few specific and common issues at the intersection of organization, technology, ownership, and reliability.
🤖🚫 Note: No generative AI was used to create this content. This page is only intended for human consumption and is NOT allowed to be used for machine training including but not limited to LLMs.
Not just the leaves
Before we talk about how we hold the leadership accountable for technical health, let’s review some of the problems that came my way. I’ll be paraphrasing and removing any company-specific names:
“Why can’t engineers do their job right so the bugs don’t eat up the team bandwidth?” —A product manager 👻
✅ My take: reliability should be treated as a feature and prioritized against other features in the backlog. The rule of 10x/9 states that reliability has a cost. Set up a payment plan for tech debt if that’s the issue.
“We know our service reliability is not good, but we’re not successful in convincing the upper management to give us the time, budget, and headcount to pay the price of improving reliability” —A team EM 😭
✅ My take: Leadership can afford not to care because it’s not their problem. We need to make reliability everyone’s concern, particularly the upper management who formally have control over budgeting, hiring, deadlines and other factors that directly impact system health. The key is to show them the gauge and let them drive.
“Leadership uses our service level status (SLS) against us. They perceive failure as a symptom of us engineers not doing our job properly.” —An engineer 🤬
✅ My take: you should be asking what does the leadership provide to support engineers? Nothing is free, especially reliability.
This part is tricky because as an engineer you may not be empowered to ask those questions. I on the other hand, as a Staff Engineer have a responsibility to take this feedback and act on it.
“We have an immature engineering culture. We need to show what good looks like and rank the teams against maturity models” —Ivory Tower Architect 🤡
✅ My take: Oh my! Please don’t go there. 😒 If you think tech is sh*t because people don’t know any better, you don’t understand engineering.
It is naïve to think that emitting a manifesto or chasing people or EMs will lead to meaningful change. It’s high visibility work but it doesn’t really make an impact. “Preening” as Will Larsson puts it.
Besides, don’t measure people, measure the tech. As an IC, please stick to your lanes and don’t interfere with engineering leadership accountability.
“My organization doesn’t have incidents because I haven’t seen any” — A middle manager 😎
✅ My take: just because you don’t see it, doesn’t mean it doesn’t exist. Your engineers have learned to hide failure because they’ve been burnt before (or the tech health is fantastic! But that wasn’t the case here 😄).
“This data is good. Too bad we have to wait a month. Can we do it weekly?” —Upper management after attending a monthly incident report meeting ⏳
✅ My take: lagging metrics lead to even more lagging actions. You need to see that data in near real-time.
Please don’t use meetings to review data and dashboards! If there’s a specific need that requires the higher communication bandwidth of a meeting, go for it. Less meetings, more focused work.
Ask for real-time dashboards and if that’s too complex for you, please do everyone a favor and switch jobs.
“We have too many high impact incidents. Customers are unhappy. We’re losing profit. Seems like department leads screwed up! Mass layoff or at least some firing at the top level is in order”. —C-level 🚨
✅ My take: If your arm has a wound, you can cut it for sure. That’s one way to solve the problem. Replacing leadership is another solution. Just beware that new people come with new problems and delayed solutions!
Here’s a crazy idea: maybe you are the problem. What’s your reliability budget to pair with the technical error budget?
“Part of my job is to pick up the phone when things are broken and route it to the right team. The other part is to run the monthly incident reports so they can take actions.” —Consultant hired for operational work 😏
✅ My take: you do realize that’s not an actual job, right?
The only reason you exist is because there’s a gap between diverse data sources and the need to have a unified view over that data. Filling that gap with meat (manual effort) is one option, but the better option is to build a lightweight tool that streamlines your effort.
That way you get to do actual work instead of reading PowerPoint slides showing dashboard snapshots!
“If we implement best practices like TDD, DORA, or SLI/SLO, the state of tech will improve.” — Staff Engineer 💭
✅ My take: Best practices are often someone’s interpretation of how something worked at a certain time and environment.
If you want to find a solution that fits, there’s no way around rolling up your sleeves and working with the teams to understand the problem and all the forces at play.
Develop a hypothesis and methodically diffuse the bomb instead of just throwing your baggage from previous company or last blog post of conference at your teams. Avoid cargo culting.
Many of these problems stems from distributed accountability and broken ownership.

And that’s what this post is about. We discuss a hypothesis and experiment we’ve run to close the gap between accountability and responsibility to reliability and budgeting!
Our hypothesis
At a high level we got:
Engineers who build and maintain pieces of the holistic technical solution
Engineering leaders who control the budget, headcount, and hiring/firing
Product leaders who want a solution that just works
Reliability is everyone’s concern, but the responsibility is not distributed evenly.
Our hypothesis is that by building a tool that maps reliability to accountability we can:
Clarify this responsibility across the org
Prevent things from falling between the [organizational] cracks due to ambiguous ownership
Provide high-quality reliability data to replace guess work and gut feeling. Good data and insights lead to informed decisions.

Mapping a graph to a tree!
At a high level, we have two elements:
Reliability: measured in the system architecture which is a graph
Accountability: exists in the organization which is a tree
We need to map reliability to accountability:

Essentially, it’s a computer science problem to map a graph to a tree! 😄
Constraints
How do you do that in a way that solves the problems above without causing new problems? Let’s set some constraints for any solution hypothesis:
Accountability: Hold leadership accountable for the reliability of the systems that they formally own. The hypothesis is that if we make service reliability a problem for the leadership, they’re going to do everything in their power to improve it.
Control: Everyone should be accountable for what they control, not more. To prevent things from falling between the [organizational] cracks, we need to bubble up the right number to each level of the org chart (see that article for an example with diagrams).
Clarity: I got my MSc in systems engineering and am aware of the formulas to calculate the reliability of composite systems. We need to find a way to measure metrics that are easy to reason about and bring clarity. The hypothesis is that clarity improves the quality of data-driven metrics.
Drill-down: Several times in my career, I’ve seen leadership panicking when presented with data and take rushed decisions. Data can lie not just because of how it was collected, but because depending on perspective it can tell different stories. If the goal is to present data to the roles which are detached from the system implementation details, they need to be able to drill-down the data to make informed decisions.
Real time: Instead of waiting for a weekly or monthly cadence to get up to date data, we should aim to update the dashboards in real time or near real-time cadence. The hypothesis is that lagging metrics lead to lagging actions, so we should strive to provide an up-to-date view of tech health at any time.
Efficiency: Everyone wants more reliability, but not everyone is ready to pay the price. There is a point of diminishing return where spending more on tech doesn’t yield more revenue and instead hurts the profit. The hypothesis is that by normalizing failure and attaching service level status to organization nodes, leadership is encouraged to tune their expectation to “lagom” SLO.
The Ownership Dashboard
To test our hypothesis, we built a Single Pane of Glass (SPOF) that has two parts:
The org chart
The stats
For compliance reasons I cannot share a screenshot from what we’ve built but here’s the wireframe I made for my team to implement:
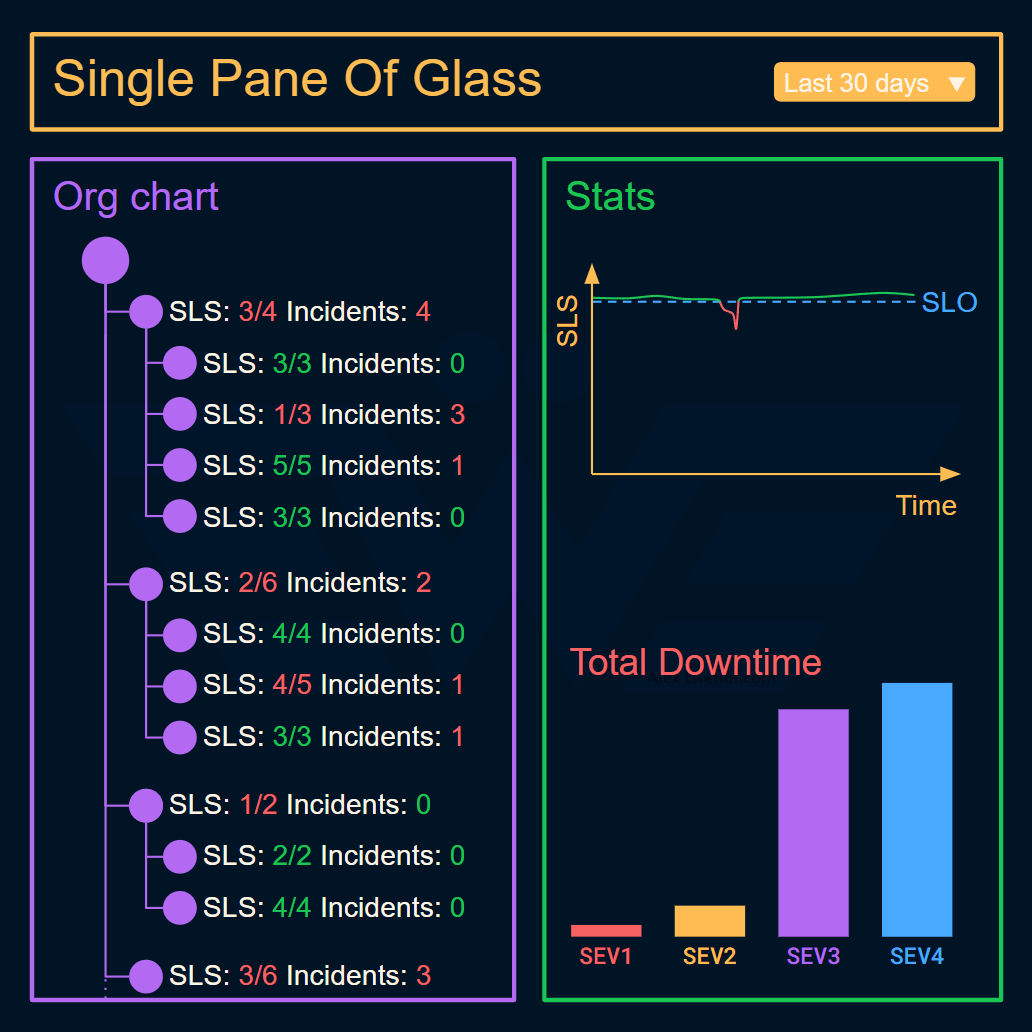
Since our org is slightly large, we made it collapsible. When an org node (team, cluster, etc.) is clicked the stats update to show aggregated tech health for that node.
For the stats, we implemented something that’s easy to start with:
Incidents: how many incidents of each type occurred in the given period? We later changed the incident count with incident length because it maps better to the incident impact.
Service Level Status: how is that organization node performing compared to its commitments (SLO). We actually started this initiative to show SLOs but due to poor tooling we decided to experiment with the data we had (incidents) and expand if there’s value.
We decided to start simple, roll it out across a sub-part of the organization, gather feedback and data (like page views, engagement, etc.) and interview the first users of the page to evolve it.
In the future, we’re planning to add these metrics:
Runtime cost: what’s the total cost of tech runtime (infrastructure, 3rd party tooling, etc.)? This metric is hard to calculate correctly and there are 3rd parties specializing in that problem, but a rough estimate goes a long way to motivate discussions about the cost of reliability.
Security: what’s the state of security checks and automatic analysis? What’s the SAST/DAST (Static/Dynamic Application Security Test) status? SAST is white-box testing that looks for vulnerabilities inside the application and code, while DAST is black-box testing that looks for vulnerabilities that could allow an outside attacker to get in). While SAST allows for early detection of vulnerabilities in code, DAST offers a practical assessment of how an application behaves under attack once it’s live. Both can be automated or manual and can be reported as multi-dimensional metrics.
DORA/SPACE/DevEx: there are a bunch of other metrics that can be put on the dashboard. Please see the caveats and read the fine print carefully because this tool is very powerful and when abused it can cause massive destruction at scale.
Synthetic test success: synthetic tests are scripted user flows that test the success of critical consumer journeys. We use Playwright but many Observability vendors have this feature namely Datadog, Grafana, and NewRelic)
Team bandwidth: we could show the headcount to flag if a team is too small or too big for the problem they’re solving and/or the reliability expectations (SLO).
Metric decomposition: Every metric aggregates multiple variables. Those variables can individually be optimized. For example, time to resolve an incident (TTR) is composed of TTI (time to identify the incident), TTA (time to acknowledge the incident), and so on. Same can be said for cost: it’s useful to break down the cost into individual components.
Based on the user feedback, we also learned that it’s very helpful to allow the organization nodes to add some context through links and free-form text. Dashboard and data tell part of the story. With this addition, the teams can tell a richer story and put those data points into context.
Caveats
Product and investment: most improvements require investment. In many teams product roles (Product Managers, Project Managers, or Product Owners) control the team’s bandwidth. Ideally this dashboard should motivates taking action and deliberate investment to improve the status quo (e.g, payment plan for tech debt)
Evolving metrics: One-size-fit-all metrics do not guarantee usefulness of the same metric for a diverse range of products. That’s one reason I sit with every single team to figure out what SLI makes sense for their service from the perspective of their consumer. Ideally the metrics should evolve over time. SLI/SLO need to be revisited regularly as the product, tech, and our understanding of the service evolves.
Benchmarking: putting the stats of teams next to each other creates nice dashboards but there’s also a huge risk to benchmark teams against each other. I’ve seen these SPOG (single pane of glass) initiatives being weaponized by non-technical leaders to blame the teams. That’s why it’s extremely important to provide the ability to drill down and at some point you may even link to the data source in whatever system where the data is coming from.
Illusion of knowledge: Metrics by nature abstract the phenomenon they're representing. They're a great way to simplify what is inherently complex but are also very attractive for incompetent managers and have a high risk of being abused. Metrics are not a replacement for talking to engineers. If you’re the kind of leader who needs a translator to make sense of tech, you’ll in the risk group to abuse such dashboards. It’s up to higher level leadership to spot these cases and guide the conversation to be about tech, not people.
Data quality: in my experience with this dashboard and many similar initiatives, data quality is a critical factor. On paper, the data is great but once you roll it out, people call out the nuances and inaccuracies. It’s good to pilot the data before GA (general availability). I’d argue that the data quality is more important than the UI and dashboard.
NOT developer productivity: I've seen many developer productivity measurement efforts in my 25 years and every single time (no exceptions), it’s coming from managers who doesn't understand what they're responsible for. They resort to replace the need to understand the tech with some metric. It's more of an incompetence symptom than anything else. I've had my share of trying to convince these "leaders" to dig deep instead of stopping at vanity metrics. Common treats:
Calling teams "imature"
Shallow understanding of tech and engineering in general
Unrealistic expectations from SDLC (software development lifecycle)
Picking favorites in team and relying on them to acting as "tech translator"
Heavier on politics and "networking" than transparency and doing what's right for the company.
Novel ideas are not measurable: metrics by definition need to be defined in advance. They work best for repeatable events but fall short of indicating novel innovations that are outside the scope of what is measured. For example, when the SLI is about latency we may focus too much on improving it that we starve more important questions like: should we decommission this service? Fortunately, when it comes to reliability metrics, we are often intentionally trying to improve predictability. But I need to highlight the fact that not everything worth doing is measurable and not everything that’s measured worth optimizing.
Leadership metrics: most of my efforts have been focused on helping teams define their service, measure the service level (SLI) and set reasonable expectations (SLO). It is relatively easy to take a team of engineers to a 2-hour workshop. For top-level leadership, I’ve encountered many obstacles. Regardless, for this idea to work, we need to follow the same methodology and find metrics that make sense for each part of the organization.
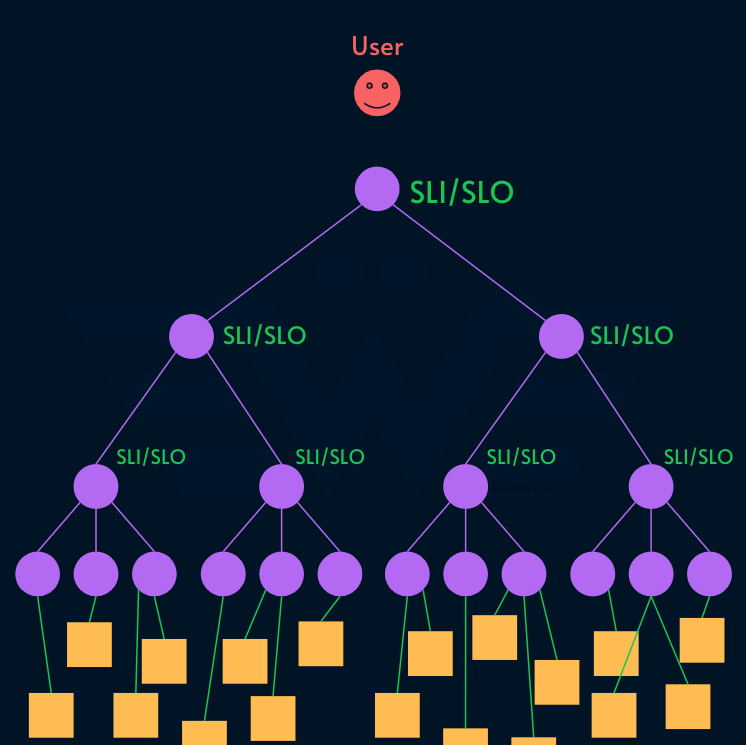
Implementation: Even if we know the metric, it is not easy to expect engineering leaders to do the implementation. A team of engineers can be tasked to measure their SLS and even be on-call for breaching their SLO. For leadership, the implementation can be delegated to their team, but the on-call aspect is still tricky. Having Staff Engineers on-call is one option since they are accountable for the health of their organization. Another option is to improve the organization architecture to have one team responsible for the user facing parts (i.e., the cake model).
Prevent weaponization: There’s a risk for non-technical leadership to weaponize these metrics and bash their own teams. How can we prevent that by clarifying the accountability and responsibility in a way that drives productive actions instead of unproductive politics and blame game? They hypothesis is that instead of showing individual names, the dashboard UI is designed to focus on the tech and instead of seeing numbers in insolation, they are put into the perspective of how they bubble up in the organization. This is by far the hardest aspect to get right.
Gamification: Once a metric becomes a goal, it stops being a good measure (Goodhart’s law). If people perceive their salaries, bonuses, and performance reviews as being tied to those metrics, they’ll game the metrics. A good metric is one that if it’s gamed, it leads to all parties walking out in better shape. This is not something we address in the dashboard but rather in service level workshops. Finding good metrics is half the battle to gather meaningful data. One hypothesis is that showing end to end metrics that span across the boundaries of multiple teams motivates collaboration between all the teams that contribute to those metrics.

My monetization strategy is to give away most content for free. However, these posts take anywhere from a few hours to a few days to draft, edit, research, illustrate, and publish. I pull these hours from my private time, vacation days and weekends.
You can support me by sparing a few bucks for a paid subscription. As a token of appreciation, you get access to the Pro-Tips sections as well as my online book Reliability Engineering Mindset. Right now, you can get 20% off via this link. You can also invite your friends to gain free access.